6.3 Case B: Logistic processes and a cardboard mill
This section describes the ME efforts carried out for
developing logistic ISs. Unlike the wholesale case, the aim of ME was not to
develop a project specific method, but rather a domain specific method. The
method was engineered by a consulting company for redesigning business processes
related to logistics. While reporting the case, we focus on method evaluation in
using the method for modeling outbound logistics of a cardboard mill.
This two-party setting is reflected in the structure of
the section. First, in Section 6.3.1 we describe the background of the method
development effort. The
a priori ME phases are described in Section
6.3.2, along with the metamodels and tools implemented. Section 6.3.3
characterizes the ISD environment in the cardboard mill and Section 6.3.4
briefly describes method use. The remaining sections focus on the
a
posteriori view: Section 6.3.5 describes the use of evaluation mechanisms
and Section 6.3.6 the refinements. The outcomes of the action research for both
case A and case B are described in Section
6.4.
6.3.1 Background of the study
The case involved two organizations: a large research and
consulting company systematizing business process re-design (BPR) practices, and
a cardboard mill undergoing BPR. This two-party setting means also two entry
points for our action research study: first to the consultant company developing
the method, and second to the mill as an application area for the method. In
this section we describe the background of the former: the consulting company
and its BPR method. The cardboard mill is described in Section 6.3.3.
6.3.1.1 Data model of logistics
The action research study was directed towards ME from the
start, because the methods and tools applied by the consulting company were
considered inadequate. The decision to develop their own method was supported by
a relatively large evaluation of logistics-related modeling tools
(Lindström and Raitio 1992) and by piloting and using various methods
(including IDEF (FIPS 1993a), communication matrices, state models, and data
flow diagrams). The method evaluations were not systematic; rather, they were
based on a trial-and-error procedure. ME was expected to support more
fine-featured method construction and tool adaptation. In fact, entry to the
company was obtained because of the decision made to apply metaCASE technology
for building tool support for their own method.
At the time the study was started, part of the method
selection process had already been carried out. The result was a metamodel of
logistic processes and ISs which can be considered as a reference model for
developing logistics (i.e. at the IRD definition level). This model was called a
data model of logistics, in contrast with reference models of logistics, which
include example solutions (i.e. at the IRD level). The data model was developed
based on experiences in developing logistics in different type of
companies.
The data model of logistics was specified by following a
variant of an ER model and by using examples. Because of the ER model, the
logistics data model included only a few modeling-technique-related constraints
(i.e. a multiplicity of a single role and an identity) and no representation
definitions. In fact, the model focused primarily on defining key concepts and
their relationships rather than modeling techniques. Examples of the concepts
were a chain, a process, a task, a job, an organization, a resource, and a
transfer (split, join, or copy). The data model was complemented by defining the
semantics of each concept and by defining major attributes of the concepts. The
objective of ME was to construct a method based upon the data model of logistics
and other model analysis related requirements. These are discussed in the
following section.
During the study, the ME effort was organized into a
separate project. The method was engineered mostly by three consultants. In
addition, some feedback about the method was obtained during pilot use from the
manager responsible for sales and delivery logistics. My role in the a
priori method construction was limited to the tool adaptation, i.e. modeling
the method according to the metametamodel applied in the selected metaCASE tool,
implementing the required checking rules and reporting algorithms, and making
connections to external tools. With respect to the a posteriori ME
principles, my role was related to introducing and teaching the evaluation
principles, and carrying out the evaluation together with the method users.
During the study the a posteriori evaluation was carried out after the
ISD project.
6.3.1.2 Requirements for the constructed method
As already mentioned, the basis for the ME effort was the data
model of logistics. Because the model focused mainly on the conceptual structure
it neither defined how logistic processes should be represented, checked,
analyzed and documented, nor considered method-tool companionship. It emphasized
concepts required for understanding object systems rather than carrying out a
change process. Therefore, the main emphasis in the ME effort was in the
analysis and model checking part: what should be checked and analyzed about
logistic processes for the purpose of re-design, and how this analysis should be
supported by a tool. In this sense, ME was driven by the formulation of the
logistic related problems to be analyzed.
In the following we describe the type of analyses which
were intended to be carried out while developing logistic ISs. Each of the
analyses raises requirements for the method construction (cf. Section 6.3.2).
The suggested analyses were partly a result of analysis needs faced in earlier
ISD efforts, and partly adopted from other methods (e.g. Harrington 1991, Dur
1992, Lee and Billington 1992, Johansson et al. 1993). The following types of
analyses were considered:
1) Minimize delays. In logistic systems it is
essential to improve the cycle time because delays increase costs. A cycle time
is the total length of time required to complete the entire process (cf.
Harrington 1991, Dur 1992). It includes working time, and also waiting and
reworking. Delays in the process are defined through tasks with the most idle
time in relation to working time. Therefore, the analysis deals with comparing
effective processing time to whole cycle time. The timing was considered to be
calculated from tasks and from transitions between tasks (cf. Harrington 1991).
Moreover, the analysis was planned to be carried out on a subset of the network
and also, if required, to the whole network.
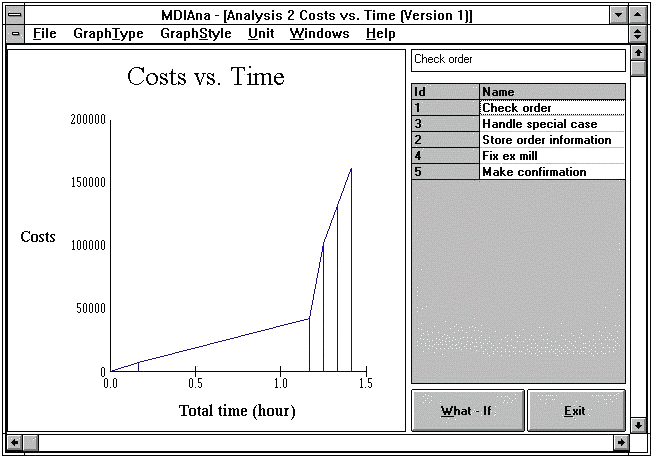
2) Minimize costs. Processes which have high costs
should be selected for further analysis. In logistics, the cumulative cost
should be analyzed together with the consumption of time (cf. Figure 6-5). This
means for example that higher costs are acceptable if they improve the cycle
time, or that small cost tasks which do not improve cycle times may not be
acceptable.
3) Minimize non-value adding tasks deals with
evaluating the process to determine its contribution to meeting customers’
requirements (Harrington 1991). In short, real-value-adding tasks are the ones
that a customer is willing to pay for. Hence, the objective is here to optimize
a process by minimizing or eliminating non-value-added tasks. With respect to
logistics, the analysis is related to cycle times and cumulated cost.
4) Simplification of processes deals with removing
tasks from the process which add complexity and make understanding of the
process difficult (Davenport and Short 1990, Harrington 1991). The result would
be fewer tasks and task dependencies which make the whole process easier to
understand. The simplification is based on analyzing processes which have
complex information flows, involve checking, inspection of others work,
approvals, creating copies, and receiving unnecessary data.
FIGURE 6-5 Cost-cycle time chart (cf. Harrington
1991).
5) Organize around processes deals with
re-designing an organizational structure based on a workflow and an overall
process structure (Johansson et al. 1993). In other words, instead of following
current responsibilities and resource allocations, the organizational structure
should be formed around the process. Here, the required analysis covers
information or material connections between workers or organizational units.
This also means that the BPR effort should not focus on modeling current
organizational responsibilities, but rather on building these based on the
workflow.
6) Minimize re-work and duplication of work.
Candidate tasks for removal can be identified from iterations in the process
(e.g. returning information), from tasks which are identical and performed at
different parts of the process, from tasks which create the same or similar
information (often by different organizational units), and from tasks which are
exceptions or correct outcomes of other tasks. The analysis of re-work and
duplication of work is performed by following the workflow of a certain item
(e.g. an order).
The focus on logistics-related analysis had the following
consequences: the method had to develop alternative solutions based on the model
data, provide concrete measures, and allow the tracking of changes in
performance with the same analysis measures. The modeling part of the method had
fewer, more general requirements: the method should resemble other used methods,
be simple and apply graphical modeling
techniques.
6.3.2 Constructed method
To understand the context of method evaluation and refinement
subjects we shall introduce here the modeling techniques and tool support. On
the method side, we describe the metamodel and how the method requirements were
supported by the method specification. On the tool side, we describe what
checking and analysis reports were implemented.
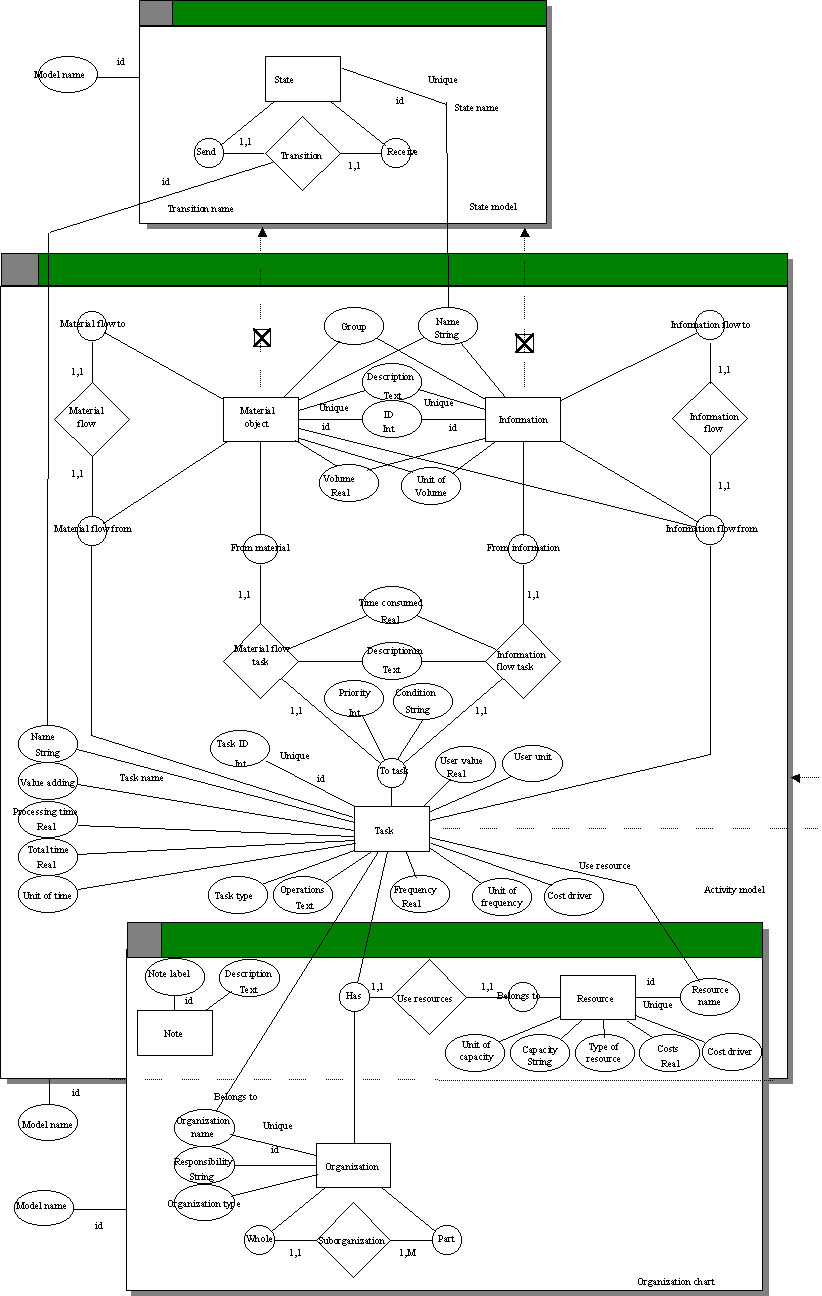
6.3.2.1 Metamodels
Method construction began by choosing modeling techniques
which are compatible with the data model of logistics. By compatible we mean
that they provide the same concepts and relationships as the logistics data
model, or allow them to be derived from the conceptual structure of modeling
techniques. The selected techniques included an activity model (Goldkuhl 1992)
for describing the workflow, and an organization chart (Harrington 1991) for
describing organizational structure. These modeling techniques were modified by
adding new types and constraints required by the analyses and by the integration
of the techniques. This task was supported by metamodeling and by reusing the
metamodel of activity modeling already included in the metaCASE tool. Figure 6-6
represents a metamodel of the techniques and their interactions. The figure uses
the GOPRR metamodeling technique (cf. appendix). The constructed method and its
relation to the analysis requirements are described in the following.
The activity model describes material or information
connections between several tasks. For this purpose, the metamodel includes
concepts of ‘task’, ‘material object’, and
‘information’. Each of these object types are characterized with
property types required for carrying out model based analyses.
The ‘task’ has an identifier as a property
type because similarly named tasks could exist. The identifier, however, could
be unique inside the method scope. An ‘operation’ property type was
applied to specify the contents of the task and possible instructions for
carrying it out. As in data flow diagrams, each task could be decomposed into
subtasks (i.e. another model). In Goldkuhl (1992) an activity (called a task
here) is characterized by its location, doer and trigger. In the constructed
version, location information was not used since it was not needed for carrying
out the required analyses. A trigger was related to flows related to a
‘task’, i.e. a ‘condition’ property type. A doer was
represented by relating tasks to organizational units. This aspect was modeled
as a polymorphism, in which the organization names are referred to by tasks and
organizational units. The implementation of the metamodel did not allow
dependency so that tasks could not refer to organizational units other than
those already specified. A similar structure would also be needed to share
resource names among instances of a ‘resource’ and the
‘task’. This deficiency also influenced the modeling process: task
structures could be specified before organizational units and
resources.
The ‘task’ has property types named a
‘processing time’ and a ‘total time’ to analyze cycle
times (requirement 1, cf. Section 6.3.1.2). The timing values were further
specified with a unit of measurement (e.g. day, hour, minute) enabling
calculation of cycle times. Cost analysis (requirement 2) was supported by
attaching a ‘cost’ property type for the ‘task’ as well
as for an ‘information flow task’ and for a ‘material flow
task’ relationship types.
FIGURE 6-6 Metamodel of the a priori
method.
The ‘task’ object type was further
characterized by its type (i.e. approval, check, decision, information update,
input, storing, transfer, or mixed). This characterization allowed the
simplification of processes (model analysis requirement 4) by highlighting
inspection and checking tasks to be removed or combined (e.g. Hammer and Champy
1993, Harrington 1991). Similarly, analysis of value adding (requirement 3) was
carried out by characterizing tasks with a ‘value adding’ property.
Value adding included four categories, (business-value-added, real-value-added,
no-value-added, mixed) and it was calculated from the estimated value before and
after a task (Harrington 1991). This characterization was also used in analyzing
cycle times and delays (requirement 1 and 2).
An ‘information’ and a ‘material
object’ were characterized by a ‘group’ property type that
combined a collection of materials or information. In this way, it was possible
to analyze workflows of specific information or material groups and identify
complex (requirement 4) or duplicate tasks (requirement 6) (e.g. all tasks
related to invoices). Moreover, the ‘information’ was characterized
with property types ‘money’ and ‘copy’. The former
specified money and the latter that the specific information was a copy rather
than the original information object. These were not required by the analysis
reports, but were included into the method to provide compatibility with the
logistics data model.
The metamodel included two basic relationship types,
material flow and information flow, which were each split into one type for task
outputs and another type for task inputs, leading to four relationship types in
all.
The ‘material flow’ and ‘information
flow’ relationship types specified outputs of a task. As in Goldkuhl
(1992) a material object can include information, but not vice versa. To model a
composite of information or material objects, the ‘information’ and
the ‘material object’ could participate in both roles of a flow.
This allowed us to describe, for example, that a delivery includes a cargo list
and shipped goods. Alternatively, an additional modeling technique could be
applied to describe composite objects.
The ‘information flow task’ and
‘material flow task’ relationship types specified inputs of a task.
These flows were characterized with a ‘cost’ and a ‘time
consumed’ property types to support analysis of costs and delays. A
‘priority’ property type was added to the ‘to task’ role
type to model urgency handling among several information or material flows. This
property was added to the role because the modeling tool did not allow
properties of relationships to be represented graphically.
An organization chart specified organizational units and a
hierarchy among them. An ‘organization’ object type was
characterized with a ‘name’, a ‘responsibility’, and a
‘type’. A ‘responsibility’ was required to identify
owners of the tasks and an ‘organization type’ classified the
organizational units into a company, a division, a department, or a working
team. Resources were modeled with a ‘name’, a ‘type’
(e.g. machine, human, IS), and a ‘capacity’. Resources were related
by a ‘use resource’ relationship type to organizations and tasks.
Therefore, the ‘resource’ can have graphical instances in both
modeling techniques. In the metamodel this is described by including the type in
both graph types (inclusion in GOPRR). Similarly, a ‘note’ object
type is used to add free form comments in both modeling techniques. It must be
noted that the ‘task’ can also refer to the ‘resource’
by sharing the values of the ‘resource name’. This possibility was
added because of the desire to simplify activity models (instead of representing
all resources and their relation to tasks with a graphical notation).
As a result, the constructed metamodel included
information about organizational units and their resources. This was considered
to support structuring of the organization according to the process (requirement
5), i.e. connections between tasks could be applied to find organizational units
which have cooperation.
It must be emphasized that not all method knowledge could
be specified with the metametamodel. Examples of unmodelable method knowledge
included mandatory property types (e.g. an identifier of the task), multiplicity
over several role types (e.g. unconnected tasks), and different scopes (e.g.
resource name unique inside the organizational unit). Moreover, method
construction raised the same requirement for a derived data type as in the
wholesale case: for example, identifiers of lower level tasks should be derived
from identifiers of higher level tasks. The lack of metamodeling power was
partly solved with checking reports as discussed in the next section.
6.3.2.2 Tool adaptation
Both modeling techniques were supported by a metaCASE tool,
MetaEdit (MetaCase 1994). As a result, models could be developed to carry out
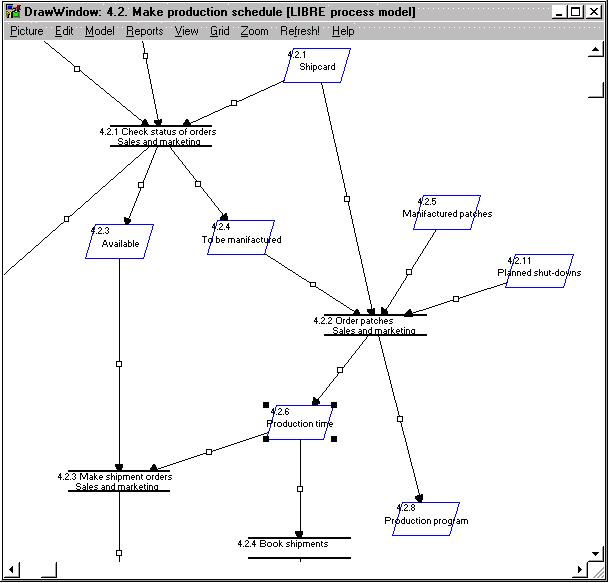
abstraction according to the metamodel. The notation of the activity model is
represented in Figure 6-8. It illustrates part of a production planning process.
As part of the method-tool companionship, reports for
checking, review, and analysis were implemented. These automated reports
complemented the manual checking and analysis. The checking reports operated on
those aspects of method knowledge which had constraints to be checked passively,
or were not possible to capture in the metamodel. The reports covered
unconnected object types (i.e. minimum multiplicity one), and undefined
properties (i.e. mandatory property types). The documentation and review reports
included a dictionary report that listed tasks, items (both information and
material), and resources. These reports resembled manual documents followed in
activity modeling (cf. Goldkuhl 1989). Moreover, tasks were also reported by
their type, possible value adding, and the people carrying them out.
Most emphasis during the tool adaptation was placed on
defining reports which carried out the required analyses based on the model
data. For the purposes of analysis, the modeling tool included a report which
transformed selected model data into the relational database format of an
external analysis tool. This tool provided the following model analysis
functionality:
| - | Elapsed
time analysis, i.e. how much time (effective and waiting time) is used in
selected tasks. This analysis addresses delays (requirement 1). Different
alternative scenarios could be analyzed using a what-if analysis by changing the
property
values. |
| - | Cost
versus time analysis, i.e. an analysis of a chain of tasks based on costs
and time consumed in each task. This analysis addresses cost minimization
(requirement 2) and is illustrated in Figure 6-5. As with the elapsed time
analysis, property values could be changed to generate alternative scenarios for
a workflow.
|
| - | Item
workflow analysis: this report describes time and costs related to a
specific item or item group. It allows the identification of errors, re-work, or
duplication of effort related to items (i.e. instances of the
‘information’ or the ‘material object’). As with the
other analysis reports, cost and time values or tasks could be changed to
generate alternative
scenarios. |
| - | Architecture
matrix: this model illustrates the creation or use of items or item groups
between organizational units. It allows the analysis of duplicate tasks
(analysis requirement 6) which create or update the same
data. |
| - | Communication
matrix: (see Figure 6-7) this illustrates the connections between
workers or organizational units. The communication matrix can be derived from
the flows of the activity model sending information or material. The
communication matrix is generated automatically from the activity model, and it
was considered to help in structuring the organization according to the workflow
(requirement 5). |
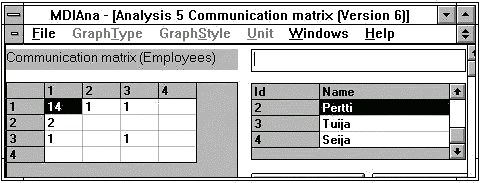
FIGURE 6-7 Communication matrix.
Each analysis report could be restricted by defining the
scope for the models to be included in the analysis. This restriction can be
made based on the version of models, selected tasks (i.e. a chain),
organizational units, groups of information or material objects, or
organizational units/workers.
In addition to these analyses, the tool generated reports
which classified tasks according to their value-adding, type, and
responsibility. The inspection of value-added properties allowed the analysis of
non-value adding processes in relation to costs and cycle times (requirement 3).
Hence, it complemented the earlier analysis. Classification of tasks according
to their type was considered to support the simplification of processes
(requirement 4). It focused on checking, approval, and information updating
tasks, which are often candidates for removal. Finally, classification according
to the responsible person allowed inspection of the coherence among individual
workers’ tasks. Each report also included additional process information
such as processing time and the description of operations or
guidelines.
6.3.3 Characteristics of the cardboard mill
The method was used in developing outbound logistics of a
cardboard mill. The mill produces specialized cardboard, mainly for the European
packing industry. The study focused on analyzing the current delivery process of
the mill. The delivery process was influenced by a cooperation with an export
association, and with companies responsible for transportation and harbor
operations. In contrast to the wholesale case, the development efforts were
limited to one company, i.e. to the mill and its parent company. Because the
problem context was logistics centered, the constructed method addressed the
characteristics of these problems in the cardboard mill.
6.3.3.1 Characteristics of the problem context
Most of the marketing and sales were made by Finnboard, an
export association of Finnish board mills. The export association provided
on-line data interchange with their customers and international sales offices.
This system provided a virtual and instantaneous means of placing status
inquiries and new orders, in contrast with the 12-day norm of the industry
(Konsynski 1993). As a result, many mills acting together and leveraging this
technology were able to appear to the outside world as one large
“virtual” company. The integrated system of Finnpap/Finnboard is
described in Konsynski (1993). Because the export association was seen to
decrease the competition among mills, its use in the form described has been
recently (and after the study was conducted) banned by the European Union. In
addition to the sales made by Finnboard, the mill had its own customers among
the subsidiaries of the parent company. These sales were made without the
assistance of Finnboard, and we call them the mill’s “internal
sales”, in contrast with the sales made by the export
association.
The main problems addressed in the ISD process related to
variation in the delivery process and poor predictability. The delivery process
varied considerably depending on the sales and delivery channel (i.e. internal
versus Finnboard). Among internal sales the variety was greater and even more
dependent on the customer. These in turn made the process more complex, which
required additional resources and increased cost. This problem had already been
detected in the mill. Its marketing manager reported that the delivery process
had recently been streamlined: all variation and exceptions had been eliminated.
However, it was still considered complex and therefore one of the objectives of
ISD was to further simplify the delivery process (requirements 4 and 6 used for
method construction). This was also of great interest to the consultants, who
wanted to apply their method and the developed tools. By modeling the delivery
process in detail, which had not been done before, it was expected that the
resulting in-depth understanding would further improve the process.
Because of the northern location of the mill and the
southern location of its main customers, transportation and logistics placed a
central role. The low costs of the cardboard compared to its inventory costs
required that the cardboard was always manufactured based on the available
transportation capacity. All deliveries were planned on the principle
“just-in-time for transportation”. Moreover, during the study the
demand for cardboard was good and the mill was operating at full capacity.
Hence, manufacturing in advance was not possible. This emphasized accurate
production planning in the mill. Therefore, ISD focused on improving timely
delivery and minimizing logistics costs. Both of these analysis targets were
taken into account in the method used(requirements 1 and 2).
It must be noted that not all aspects of the method were
considered to be needed. They were, however, included in the method used because
these additional analyses had not been used in earlier ISD efforts. In this
sense, the experiences of the consultants are counted for the constructed method
rather than as a priori identified characteristics and problems of the
mill to be addressed.
6.3.3.2 ISD experiences and method knowledge
The cardboard mill had limited experiences with ISD methods.
In contrast, the consultants responsible for carrying out the effort had
relatively high expertise in methods and method selection. This was also
indicated from the existence of the data model of logistics and earlier cases
from other companies. One of the consultants had studied artificial intelligence
systems for contingency-based method
selection.
6.3.4 Method use
The ISD project took place in the cardboard mill but also
included personnel of the parent company. The project took almost one year, and
around twelve people were involved. Most effort was spent on specifying
production planning and delivery. During the project these processes were
represented by 90 tasks, 140 different information flows, and 30 material flows.
An example of a model related to production planning is illustrated in Figure
6-8. The model is based on the activity modeling technique.
Modeling began by defining task structures and validating
the activity models. This took most of the time related to method use. Once the
task structures had been validated they were refined by adding properties about
individual tasks and flows. At the same time the task structures were
supplemented with organizational structures and by connecting resources to the
tasks. This step was supported by the organizational structure chart.
The models were divided into those dealing with internal
sales and those dealing with Finnboard sales. The analysis of the processes was
conducted according to the analyses discussed in Section 6.3.2.2. Without going
into details, all tool-supported analyses, except those related to cost, were
carried out. Cost-related modeling and analyses were not performed because of a
lack of time. The project outcomes included three major recommendations to
improve production planning and delivery.
First, the delivery process had to be simplified by
removing variation in the process. This result came as a surprise. For example,
the marketing manager stated: “I thought we had already streamlined our
delivery process, but now we have to streamline it some more”. The report
of the development project summarized that although the variation was not
considered remarkable, it doubled the resources needed. The extra complexity was
most notable in internal sales. The modes of operation were more homogeneous in
Finnboard sales. This could be easily detected by comparing the workflows (e.g.
tasks involved and resources needed).
FIGURE 6-8 Model of production planning tasks
(modified).
Second, better principles for exception management were
needed: exceptions took more than half of the total time in delivery management
(analyzed through elapsed time, and item workflow). One reason for the
relatively high rate was unclear and varying responsibilities. For example, when
a change occurred, notification to other parties in the delivery process was
haphazard and each party (customer, mill, harbor, transportation company, ship)
made and requested several unnecessary confirmations.
Third, internal sales included tasks which duplicated
effort. Tasks such as checking order validity and saving order information were
not relevant. Because of the variation, one proposed option was to make the
internal sales more similar to that of Finnboard sales. This would necessitate
consideration of the current service level in which the mill would take into
account the special requirements of each subsidiary company. The resulting
better predictability would help production planning.
More detailed analysis of the processes was not possible
for two reasons. The variation in the process required that the model-based
analyses addressed average situations and excluded frequencies. Furthermore,
analysis of cost and value analysis was not
conducted.
6.3.5 The a posteriori method engineering
In this section we explain how the method was evaluated and
refined. We first apply type-instance matching: this part was conducted by the
method engineers. Second, we assess the applicability of the method in terms of
how well it supported business modeling. Third, we identify the role of the
method in problem solving. These latter two evaluations were carried out by the
method engineers.
6.3.5.1 Type-instance matching
Type-instance matching inspects how the constructed method has
been applied. The comparison is made between the method’s intended use (as
seen from the metamodels) and actual use (as seen from the models). In the
following we describe the results of this evaluation, i.e. the differences
between models and metamodels which suggested method refinements (cf. Section
5.3.3 for details).
6.3.5.1.1 Usage of types
1) Unused types. Because the analysis reports required
detailed data the method was followed strictly. For example, analysis of delays
required time related properties to be specified (i.e. have values). Some
property types, however, were used infrequently. These included the property
types ‘money’ and ‘copy’. Second, property types
characterizing flows were not applied. Therefore, analysis of delays did not
include time consumption related to flows. Third, costs related to tasks or
flows were not modeled. As a result, these property types could be removed from
the method.
2) Division or subtyping was not required because
modeling constructs were not overloaded. The main reasons for this was that the
use of the ‘group’ and ‘type’ property types allowed for
user-defined classifications. The analysis of the free form
‘operation’ property type, however, indicated new data types. Some
tasks included data about error rates and frequencies which could be included as
new property types and used in analyses.
3) Definition of new linkages between types was
suggested in only one situation. ‘Responsibility’ and
‘resource name’ had the same values. This suggested polymorphism, to
make existing values available between these property types. This would speed up
modeling and decrease typing errors. Several task names also included
information or material object names. For example, a task called “refine
annual budget” delivers as output an “annual budget” which is
an instance of the ‘information’ object type. This is illustrated in
Figure 6-9. However, refinements could not be made here because in some modeling
situations the value of an information or a material object was either an input
or an output, and the name of a task did not necessarily refer to any
information or material object. These naming-based connections, however, could
be checked using reports. For example, a report could inform of tasks which did
not refer to any of the related information or material objects.
6.3.5.1.2 Usage of constraints
Analysis of constraints was limited to those defined in the
metamodel and supported by tools. It must be noted that although the
metamodeling language did not support all constraint definitions, the tool
checked some of the omitted constraints passively using reports. These reports
identified violations of the unique property, mandatory property, and
multiplicity constraints. The first two of these in particular were needed to
carry out model-based analyses. An identity constraint related to one property
type was not enough since there was a need to distinguish versions. This defect
was solved by extending all model data with a version number during a conversion
of the models. Similarly, checking of unused property types informed about
values which were not yet specified but were required by the reports. The model
data, however, was often supplemented in the analysis tool because passive
checking did not guarantee model completeness. If all property types had been
defined as mandatory while making preliminary task structures, entering all task
specific data would not have been possible. Alternatively, a weaker constraint
technique could be created for modeling preliminary task structures.
A uniqueness constraint was defined only for identifiers.
The tool actively ensured the uniqueness of identifiers. The data types defined
were found to be adequate, although the predefined values needed some
refinement. As storage and transfer were not used while classifying tasks (i.e.
the ‘task type’ property type) they were removed. Value adding was
not applied as planned because the classification was too detailed. Instead, a
Boolean value (valued-added, no-value-added) was found to be
sufficient.
The cardinality constraints in the activity model were not
changed. Flows which split or join information or material objects could be
created by attaching additional instances to an instance of the
‘information’ or the ‘material’ object types.
Constraints on role multiplicity could not be specified
adequately in the metamodel. Instead. reports inspected connected and
unconnected object types. Model data suggested that in a model scope the
‘task’ should have a minimum multiplicity constraint (one) for all
related role types (i.e. ‘material flow from’, ‘process
to’, and ‘information flow from’). An
‘information’ and a ‘material’ should have the same
minimum multiplicity, but on the scope of the whole method. Hence, in a single
model, an instance of ‘material’ or ‘information’ should
participate in at least one role, but inside the method in all possible roles,
i.e. be both an output and input to a task. This necessitated the use of a
multiplicity constraint over several roles.
The metamodeling language did not support checking of
cyclic relationships. Therefore, possible cyclic relationships between
organizational units (e.g. department consist of itself) could not be checked
actively. The tool reports allowed checking only direct cyclic relationships and
thus here the method implementation was inadequate. In activity models direct
cyclic relationships could be denied because they take part in several object
types. For example, the metamodel did not allow direct connections between tasks
and thus required information flow or material flow based connections. The
method, however, allowed direct cyclic relationships to be created between
information and material objects. The initial objective for allowing cyclic
relationships was to keep the method simple and use flow relationships to model
whole-part structures. Figure 6-9 illustrates the whole-part structure in an
activity model in which a budget consists of other information items.
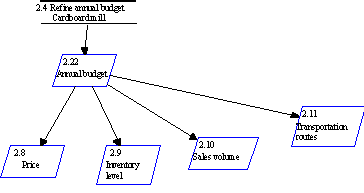
FIGURE 6-9 Modeling whole-part structures in the activity
model.
Type multiplicity could not be defined in the metamodel
and the tool could only inform about the number of type instances in a model, or
in the whole method. Based on the model data, all object types except
‘material object’ and ‘resource’ should have a minimum
multiplicity constraint of one in the scope of a model. Because not all activity
models included instances of ‘material object’ and
‘resource’ the scope for type multiplicity should be the method. As
a consequence, information flows and suborganization relationship types should
have instances in all models. The maximum multiplicity constraint was not
changed because the models were not considered to be too large (e.g. the largest
model had 34 object type instances).
The specification of task hierarchies had several errors
because neither the metamodel nor the tool could enforce the complex object
constraints. The metamodel only allowed the specification of non-mandatory
components, and the reporting capabilities of the tool did not support the
checking of complex objects. The required checking included exclusivity of
components as well as aggregated relationships. At best, the tool could produce
reports which collected constraint-related data for manual checking. This
naturally led to error-prone and tedious model checking, decreasing the
reliability of analyses.
Polymorphism was applied in two cases in which a task
referred to an organizational unit and to the resources it used. Instead of
referring to the value of a property type the reference could include the whole
object type. In other words, instead of referring to an organization name a task
could refer to the whole organizational unit. The advantage was the possibility
to inspect specifications (i.e. properties) of organizational units and
resources during activity modeling. Hence, the polymorphism unit would be the
whole object instead of a single property. Finally, instances of
‘responsibility’ and ‘resource name’ had the same
values. This suggested a polymorphism structure: sharing the same instance value
between these property types.
6.3.5.2 Modeling capabilities
The method was constructed to support logistic analyses. In
the following the modeling capabilities are analyzed using the evaluation
mechanisms. The suggested refinements are summarized in Section 6.3.6 as changes
in the metamodel.
6.3.5.2.1 Abstraction support
The use of the method raised new requirements for describing
the logistic processes of the mill. First, there was a suggestion that the
life-cycle of important information and material objects would be modeled in
separate models. By the life-cycle we mean all the states of an information or
material object and transitions between these states. Examples of the states of
a material object representing an order are received, checked, accepted,
delivered, invoiced, etc. The activity model primarily described sequences and
connections between tasks, but the life-cycle of each item was scattered over
several models. Only analysis reports illustrated the life-cycle concept through
tasks which related to a certain item, or item group. Second, the consultants
suggested a new property type which could be defined in modeling (i.e. typed
during modeling). In the mill case, tasks in particular were considered to need
extra information about error rates or broken items. The addition of a new
property type instead of free-form description data in the current
‘operations’ property type was emphasized because the analysis tool
required structured descriptions. Third, it was suggested that information and
material objects could include information about volume data and a property for
free-form description.
Major difficulties in modeling were related to the
variation in the business processes. Two kinds of variation were detected.
First, the delivery process differed greatly depending on the type of customer,
tasks involved, and task specific properties. This could not be solved by
modifying the modeling technique but rather by introducing generalizations (e.g.
typical, problematic, etc.). Hence, the developers needed to introduce different
versions (e.g. internal sales versus Finnboard sales) and find representative
cases of the processes in each version. A second kind of variation related to
frequency. The method expected that task characteristics remained stable and
volatility could not be modeled. For example, an exception in the process could
increase workload temporarily and cause long-term delays. The proposed solution
for this deficiency in the method was a ‘frequency’ property type
attach to the ‘task’.
Because modeling work was carried out by two people, and
others mostly reviewed the models, no major modeling differences between
participants were detected. Moreover, the consultant acted both as a method
engineer and an IS developer, and could explain and teach the method to other
stakeholders.
6.3.5.2.2 Checking support
During model maintenance most efforts focused on the task
hierarchy and on the property type ‘task’. This needed to be
consistent within the hierarchy. Because the metamodel did not adequately
specify these constraints (i.e. a complex object) the resulting models had
several inconsistencies. For example, it was required that the modelers updated
the aggregated relationships in a task hierarchy and that tasks were exclusive
(cf. constraints for complex objects in Section 4.4.2.2). The variation in the
process emphasized maintainability problems because a change in one task
required changes in other models.
The task hierarchy highlighted property-based dependencies
between tasks. For example, the processing time of a task should not be less
than the processing time of its subtasks, or a task should not be defined as
value-adding if none of its subtasks were value-adding. This demanded creation
of a new data type which allowed derivation rules to be defined and related to a
selected set of property types. Similarly, the numbering of tasks based on a
task hierarchy required a lot of manual work: it was the modeler’s
responsibility to update identifiers when the task hierarchy changed. To speed
up the modeling process it was suggested that the tool would use internal
identifiers (and output these to the analysis tool). Similarly, to speed up
modeling work, timing-related property types needed to include measuring units.
The initial metamodel included a pair of property types, i.e. one for the value
and one for the related unit. Both these requirements were surprising because
they were not found during the initial method analysis (Chapter 4).
6.3.5.3 Problem solving capabilities
The method was constructed to automate analysis tasks. Hence,
the form conversion and review capabilities were emphasized during the
evaluation of the method. Surprisingly, most benefits were outcomes of modeling
rather than of analyses. Although most tool-supported analyses were carried out,
their contribution was disappointing. The automated analyses found few
improvements and their results were considered dubious because of different
interpretations. Instead, most benefits of analyses occurred from the
identification of those aspects of processes which required further analysis
(e.g. the most time consuming tasks, or slack resources). It must be noted that
not all analyses were relevant in the mill case, but all were included since the
consultants wanted to test the whole method.
6.3.5.3.1 Form conversion support
Form conversion denotes a tool’s capability to analyze
models and generate candidate designs. In the CASE environment the conversion
functionality was provided through analysis reports. Accordingly, we evaluate
the tool’s contributions to analysis of the model data and identification
of design solutions.
1) Delays were analyzed by inspecting the elapsed
time in tasks. The delay analysis revealed that exception management is
time-consuming, and that internal sales are over 20% more time-consuming than
Finnboard sales. Although the analysis allowed the comparison of effective time
and waiting time, candidate designs to optimize processing time were not sought.
In other words, no what-if analysis was carried out. Reasons for the limited use
of analyses included difficulties in choosing candidate times and volatility in
the object system: in many tasks time related measures were considered
inaccurate because of wide deviations in the processing time, and because flow
times were not specified. As a result, the analyses were considered unreliable.
The solution suggested was to add frequency information to the
‘task’. Although this information was not supposed to be modeled
during activity modeling, but rather during analysis, it was added to the
modeling technique, to help gather frequency data while modeling time
properties.
2) Cost analysis was not carried out because
gathering costs via task structures was difficult, and the project lacked the
necessary resources. Hence, all cost-based modeling constructs, including the
cost-cycle time chart, were not applied. Because of these difficulties the
consultants examined accounting-based approaches which could be used with
current modeling methods. In ABC-based accounting (Morrow 1992) the resources
would have the cost data and cost drivers. Moreover, tasks would then be linked
to resources (as in our models) and to task specific cost structures. Hence,
instead of relying on task costs, the cost analysis would be based on resources
costs. ABC-based accounting would require linkages to external tools, such as a
spreadsheet application.
3) Value adding was not related directly to the
analyses because its use was not possible because of the limited cost analyses.
Instead, reports of value adding capability were applied to identify removable
tasks, i.e. non-value-adding tasks. During modeling, however, the value-added
features had been understood so strictly that less than 10% of tasks were
specified to add value. Moreover, internal sales had more non-value adding tasks
than Finnboard sales, indicating that the mill should perform the minimum
possible outbound logistics by itself and leave the rest to the export
association. The value-adding was considered to be improved by relating it to
the cost-cycle time chart: cost and delay analysis would then support analysis
of value-adding activities.
4) Simplification of processes was performed by
streamlining the delivery process. To this end the effort focused on exception
management and the redesign of sales processes. Most of the simplification
possibilities were detected during the modeling step, but the automated analysis
allowed comparison of item-based workflows between different sales channels
(i.e. internal sales vs. Finnboard sales, and internal sales to different types
of customers based on delivery terms). Because cost data was not available this
analysis relied on elapsed time only and had the same difficulties with
inaccurate results.
5) Organize around processes. At the level of
individual workers the communication matrix did not find strong bindings between
workers in different organizational units. Hence, the organizational structure
seemed to follow the task structure already. At the level of organizational
units the communication matrix was more useful: it allowed the inspection of
differences between internal sales and Finnboard sales. In the former case, the
mill had a lot of connections with other parties, e.g. haulage, harbor, and
customer, whereas in the latter case, the export association managed most of the
negotiations with other parties. However, because the project focused on the
mill, no suggestions were made about how to organize the responsibilities in the
network.
6) Minimize re-work and duplication of work.
Candidate tasks to be removed were sought using the architecture matrix and the
item workflow. The architecture matrix showed tasks which created or updated the
same data and thus pointed out tasks to be removed or combined. Item workflows
described iterations in the process and thus clarified the repetition of work.
During the analysis the architecture matrix revealed possibilities for
re-designing processes based on access rights (i.e. create, use). Item workflows
did not reveal why work needed to be repeated.
To summarize, the architecture matrix was the only
analysis which directly enabled the generation of designs. The candidate designs
could be made by changing the data access rights for tasks. Other analysis
reports measured the current situation, but did not include any built-in
possibilities to suggest candidate designs. These reports were supported with
what-if analyses, i.e. by changing the values in the analysis tool and running
the analysis again.
6.3.5.3.2 Review support
Most method use was concerned with validating models with the
domain experts. Hence, the review support was of great importance. In a CASE
tool, review support implies the production of documents for different
stakeholders to validate the models.
Validation was performed in two phases: first related to
the general task structure and organization structure, and second in relation to
the details of the models (i.e. to properties used in analyses).
In the first phase, the review was carried out using
graphical models. The main difficulties while reviewing the models concerned
dividing flows and specifying volumes. Initially, the method included only a
‘condition’ property type for describing dividing flows. The domain
experts suggested that dividing flows should be specified in more detail, e.g.
by describing logical operators or a ratio. An example of such a situation is
shown in Figure 6-8 in which information about production time (ID 4.2.6) is
used in two tasks. The use of logical operators (and/or), as proposed by
Goldkuhl (1989), would allow the modeling of situations where the information
object is used in both tasks or in one of the tasks. Moreover, users suggested a
percent-based specification showing, for example, that in 40% of the cases the
information was used by only one of the tasks. Moreover, the condition values
were not shown in graphical models and thus they suggested a notational change.
The users also suggested that volume information should be shown graphically.
This addition required a new property type for the ‘information’ and
‘material object’ types, with a new notational element (i.e. a text
field close to the rectangular symbol of the ‘information’ and
‘material’ object types).
Although these additions were simple, their influence on
the model analyses (e.g. item workflow) was unclear. It was suggested that each
analysis case be handled separately either by modeling all conditions
separately, or by omitting the conditions during the transfer of data to the
analysis tool. In the latter case, the conditions should be entered while making
a what-if analysis.
In the second phase, the review focused on validating the
property values. For this task we developed a report tool for documenting the
tasks of each individual, who could then review the information. These
documentation reports were also included into the final report. In addition to
personal reviews, the method users proposed state modeling to collect and
integrate workers’ views into state models. This was believed to help
inspect the dynamic behavior of order management independently of workers’
tasks. It could therefore offer a behavior-oriented view to help validate task
structures (i.e. the process oriented
view).
6.3.6 Method experiences and refinements
Method evaluation provided a good amount of experiences of the
method and suggested several method modifications. Method development focused
mainly on analysis needs and emphasized modeling constructs which were needed by
the analyses.
The method refinements suggested were a direct outcome of
the method evaluation. The evaluation clarified that the most important changes
related to modeling life-cycles of information or material objects, managing
variation in time, and describing volumes. These are reflected in the metamodel
illustrated in Figure 6-10. It should be noted that not all metamodel
constraints, such as scopes, are captured in the metamodel because neither the
metamodeling language nor the tool supported them adequately.
FIGURE 6-10 Metamodel of the refined method.
A simplified state model was considered adequate to model
the life-cycle of information and material objects. The simplification meant
that events and conditions typical in state models (cf. metamodels in Section
4.3) were excluded. Instead, the state model was integrated to the activity
model through explosion and polymorphism. Explosion meant that each
‘information’ and ‘material object’ instance was linked
to a state model. Although the cardinality of the explosion could not be
specified in the metamodel the explosion should be mandatory for
‘information’ and ‘material object’ instances and
“floating” state models should not be possible (i.e. the cardinality
of the explosion should be one-to-one for the source and one-to-many for the
target state model). Checking of cardinality constraints is passive because we
wanted to leave unspecified whether activity models or state models should be
created first. This metamodeling choice also influenced the dependency of
polymorphism structures.
Polymorphism was defined between two techniques: values of
the ‘name’ property type characterizing the
‘information’ and ‘material object’ types were shared
with ‘state name’ values. Similarly, ‘task name’ values
were shared with ‘transition name’ values. While using the method
this method specification would allow the modeler to refer to existing property
values instead of entering the same values twice or more. As a result, modeling
becomes faster and less error-prone, and model changes are reflected
automatically in the tool. Another possibility would be to refer to the whole
information or material object instead of a single property. This possibility
was not used because the tool did not support it. The polymorphism allows
inspection and checking of models. For example, each transition should be
represented for a task in an activity model, and all states should be required
as information or material objects in some activity model. It must be noted that
the polymorphism could not be defined to be dependent because the explosion
cardinality did not expect that either of the techniques should be used first.
Hence, the polymorphism was checked passively at the user’s
request.
Activity modeling was simplified by removing some unused
property types: ‘money’, ‘copy’ and ‘costs’.
To enable calculation of delays and costs, the ‘information’ and
‘material objects’ were supposed to be characterized with volume
information. The ‘task’ object type was refined by relating property
types for specifying frequency and user-defined aspects. Although the ISD effort
indicated that error rates could be specified with their own property type, it
was considered to be specific to the cardboard mill only. Hence, user-defined
values were expected to be more flexible in future. Moreover, to specify more
detailed descriptions about activity models a new property type
‘description’ was attached to information and material object types
and flows.
The modeling experiences showed that costs are difficult
to collect in a similar manner to other workflow characteristics. Therefore, the
cost analysis was changed totally: instead of adding cost information to
individual tasks and items (i.e. material or information) they were related to
resources. The cost structures were calculated through Activity Based Counting
(Morrow 1992). Because the modeling tools used were not well-suited to
accounting, the tool would export cost data into a spreadsheet. For this
purpose, the ‘type of resource’ was supposed to refer to the kind of
cost, and the ‘capacity’ to a cost driver. Information about the
resource use of each task could already be modeled with the method.
To support model review we considered it necessary to show
more design information graphically. Because the tool could not show properties
related to relationship types, the ‘condition’ was moved to the
‘to task’ role type.
In addition, the evaluation suggested changes to the tool.
First, the tool should allow graphical selection of a task chain and transfer it
into the analysis tool. Second, the predefined reports for documenting and
checking were suggested to be improved, enabling the use of passive constraints
(e.g. cardinality of explosion). Alternatively it was suggested to automate
passive checking while transferring the models into the analysis tool. This
option was abandoned because it would slow the transfer of models into the
analysis tool. Third, the numbering of identifiers should be automated.
The method evaluation also allowed improvements in
activity modeling, method related contingencies, and automated analyses.
Activity modeling was considered to be easy to use, its models were
understandable, and communication with end-users improved. As already mentioned,
the main difficulties were related to maintaining task hierarchies and
identifying codes when models changed.
Second, because a priori method selection did not
follow any contingency selection framework, the relevance of method selection
criteria could not be measured. Instead, during method construction the
compatibility with earlier experiences with the logistics data model were
emphasized. After all refinements it was interesting to notice that the
refinements included no major changes which conflicted with the underlying data
model. Instead, the original data model was extended with some behavior-related
concepts.
Third, the automated analyses were disappointing when
compared with the original objectives. The analysis reports did not originally
allow the generation of candidate solutions, and the analysis results often
looked doubtful. Maybe the case was too complex for the required analysis, and
the given measuring properties too inaccurate because of the variation in the
process studied. It was therefore suggested that the analyses would be tried out
in smaller, more bounded business systems. Accordingly, principles should be
sought for choosing between alternative workflow scenarios (e.g. product based,
customer based, worst case, etc.).