5.3 Principles for incremental method engineering
In this section we shall describe principles for a
posteriori and continuous method engineering. These principles are described
through the steps of incremental method engineering, and the mechanisms applied
in each step. The steps deal with collecting experiences, analyzing experiences,
and refining a method for a current situation. These steps are lacking from
other ME approaches and together with a priori ME they form an
“iterative loop” of incremental ME. Hence, we claim that both a
priori and a posteriori steps are required. The a priori steps
were already described in Section 3.2 and the a posteriori steps are
described in the next section (5.3.1).
Throughout these steps we apply three mechanisms that seek
to improve methods. These mechanisms are based on analyzing the differences
between an intended and actual use of modeling techniques (Section 5.3.3), on
studying the role of techniques in modeling object systems (Section 5.3.4), and
on understanding how they support problem solving (Section 5.3.5). As the review
of method evaluation approaches showed, these mechanisms are not the only
possible ones. They are relevant for improving tool-supported methods and
managing methodical changes through metamodels. Together with these method
refinement mechanisms, we apply metamodels and method rationale to collect and
analyze experiences as well as refine methods (Section 5.3.2). In comparison
with other evaluation approaches these make the method improvements more
systematic and render refinements
visible.
5.3.1 Process of incremental method engineering
To extend the a priori view of ME approaches we propose
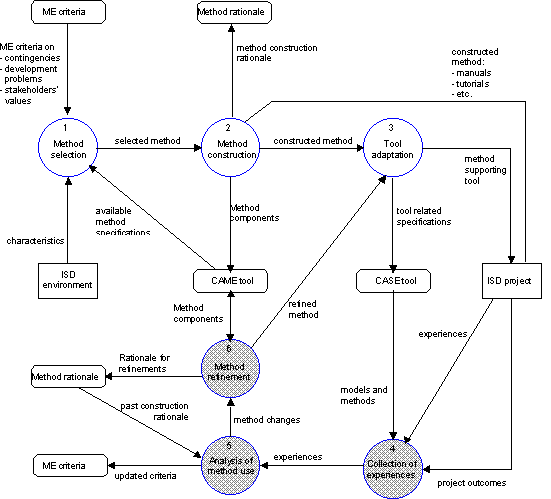
some complementary principles. These extensions are illustrated in Figure 5-2.
The data flow diagram shows the steps of ME, with the three steps of incremental
ME illustrated by grayed processes. These steps deal with gathering experiences,
analyzing method use, and refining a method. Together with the a priori
steps, they form an iterative cycle in which method improvements can take
place gradually using method stakeholders’ experience (cf. Checkland
1981). In the following we shall outline each step and their linkages to the
steps of a priori ME.
FIGURE 5-2 A data flow diagram specifying the incremental
method engineering process.
In carrying out experience-based method evaluation the
accuracy and availability of feedback must be enhanced. This improves
experience-based learning (Huber 1991). The accuracy of collected experiences is
enhanced by relating experiences to metamodels and to the method construction
decisions. Their use is discussed in more detail in Section 5.3.2. The
availability of method use experiences is enhanced by collecting models and
metamodels, by collecting outcomes of an ISD project, and by interviewing
stakeholders. The collection of models as deliverables is similar to the ideas
proposed by Fitzgerald (1991) and Schipper and Joosten (1996). Models provide
data on how modeling techniques were actually used. Because we focus only on
meta-data models, the models only describe the end-result of method use rather
than the modeling process. In the context of metamodel-driven modeling tools,
the collection of models and metamodels can be automated since they are both
stored in a repository of a metaCASE tool.
In addition to the model-based deliverables, the outcomes
of the project are inspected. These deal with the results of the ISD process
changing or improving the problem situation of the object systems. Interviewing
method stakeholders obtains situational experiences of method use. Both
unstructured and structured interviews can be used for data collection. An
unstructured interview closely resembles a normal conversation and allows a
method user to apply his or her own concepts and aspirations to specify method
refinements. Typically a refinement demand becomes apparent from the
modelers’ observations of the limitations of a method in use situations
(e.g. Tollow 1996, Jaaksi 1997). Structured interviews are based on predefined
questions which are known to reveal refinement possibilities. The mechanism of
incremental ME described in the remaining sections of this chapter forms the
basis for questions for the structured interviews.
The second step deals with analyzing experiences in order
to improve a method. This step is carried out by the mechanisms of experience
analysis described in the following sections (cf. Sections 5.3.3-5.3.5). In
short, the mechanisms deal with:
1) Type-instance matching: inspecting differences
between an intended (i.e. metamodel) and actual use of a method (i.e.
models).
2) Modeling capabilities: analyzing the capability
of the method to abstract required aspects of the object systems into models and
to keep them consistent.
3) Problem solving: analyzing the capability of the
method to generate alternative solutions and support decision making.
The mechanisms are designed so that they reveal those
aspects of a method which can be a target for refinements. In other words, if
the analysis phase suggests a method modification it reveals that the a
priori constructed method was not sufficiently applicable.
Evaluations of method use can lead to modifications of
method knowledge and tool support. Modifications related to the conceptual
structure or notation take place by adding, subtyping, joining and removing
components of the metamodel and by specifying a related notation. Each of the
metamodel-based refinements can be operationalized through the same metamodeling
constraints as in the method construction (cf. Section 4.4). The re-constructed
method is stored into a CAME tool, from which new components can also be
selected. Tool re-adaptation is a necessity if a metamodel has changed (cf.
method refinement scenarios, Section 5.1.2). Not all refinements, however,
necessarily require changes in the method. There are changes that deal with the
way the method is supported by the tool. For example, the consistency of model
data can be improved by adding checking reports without modifying the metamodel.
The modification of a CASE tool must be emphasized, because the advantage of
method improvements comes when the refined method is used in a modeling tool.
This enables the sharing of refinements and makes possible a new evaluation
cycle.
An improved method is not the only outcome of the
incremental approach, because the evaluation allows the creation of new
knowledge for future ME efforts. Based on current ME approaches this knowledge
should be related to the ME criteria in two ways: to confirm or to reject the
criteria used in the method construction, or to add totally new criteria. In
fact, the only way to use frameworks of ME criteria is to “fill”
them with criteria that have worked in past situations. This necessitates that
the realization of ME criteria is assessed in terms of new criteria, changed
criteria, and whether the
a priori set of criteria is still relevant.
This means that method engineers should analyze the ISD environment
continuously, not just for the initial method construction. Paradoxically, ME
approaches which aim to apply available frameworks of ME criteria have neither
validated them nor considered how information about situational applicability is
found.
5.3.2 Use of metamodels and method rationale in incremental method
engineering
As with most attempts at organizational improvement,
improvements to the current state are difficult to make if the practices
currently followed are not known. Changes can be made but no information is
available on the effects of the change nor whether they can be considered as
improvements. Similarly, incremental ME can not be carried out effectively if
information about a method and reasons for its promotion are not known. The
former, method knowledge, is described in metamodels, and the latter, method
rationale, is described in ME criteria and decisions made during method
construction. Both of these are used to collect, structure and analyze
experiences. Use of them increases the accuracy of the cause-effect
relationships between an engineered and a required method. Their use in ME is
described in the following.
5.3.2.1 Metamodels in incremental method engineering
As in method construction, a metamodel makes method knowledge
explicit. Incremental ME applies metamodels beyond the method construction step.
In the first step of incremental ME, metamodels provide a mechanism to collect
and structure experience: method stakeholders’ comments, observations, and
change requests can be related to the types and constraints of the method. This
helps make experiences explicit, and helps focus on those experiences which are
related to the method.
For the analysis step, metamodels allow the detection of
those parts of the method which are subject to further analysis. The analysis
possibilities are available through the same metamodeling constructs that were
applied in describing the method. As in method construction, alternative method
refinements can be made and compared by using the metamodeling constructs.
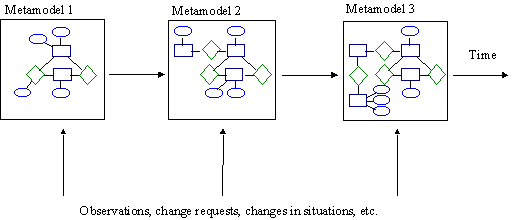
During an iteration of the incremental approach, metamodels provide a history of
method refinements, since all changes to the method can be found by comparing
metamodels made at different points of time. Figure 5-3 illustrates the method
evolution through “constellations” of metamodels.
FIGURE 5-3 Method evolution in metamodels.
5.3.2.2 Method rationale in incremental method engineering
Metamodels alone are inadequate to manage method refinements,
because they can not explain the evolution of a method. Therefore we need method
rationale. Method rationale occurs at two different levels depending on the
users (Jarke et al. 1994, Oinas-Kukkonen 1996). For method engineers, method
rationale is an explanation why certain types or constraints of the method are
included in the constructed method. We call this a method construction
rationale. Ideally, each type and constraint in a metamodel should be justified.
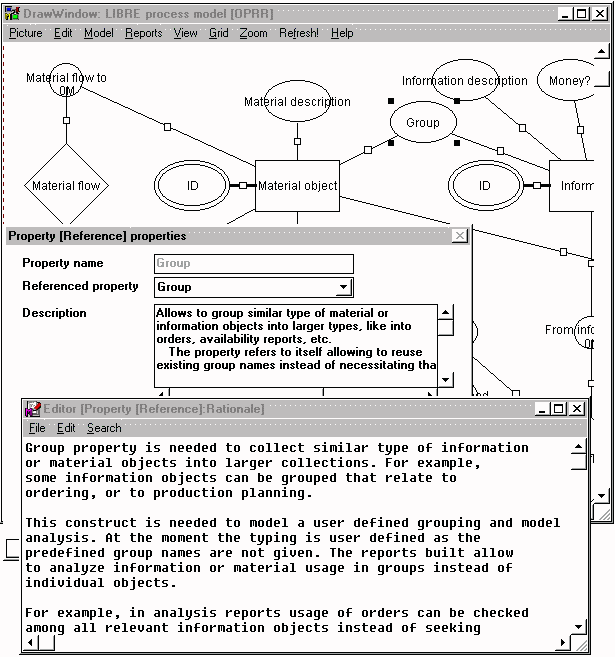
A sample of method construction rationale from our action research study (cf.
Chapter 6) is given in Figure 5-4, in which an explanation for a
‘group’ property type is given.
The topmost window describes part of the metamodel in
which a ‘group’ property type is defined. The middle window shows
specifications relating to the property type. These include the name of the
property type, that an instance of the ‘group’ refers to values of
existing groups, and an explanation of the type for method users. The lowest
window describes the reason why the ‘group’ property is needed. In
the example, the rationale for using the grouping is the need to collect similar
kinds of information or material objects. For example, an analysis can include
information about business processes which only use information related to
orders, such as sales orders, quick orders, repairing orders, orders sent by
someone other than the original customer, etc.
Instead of applying a predefined schema for method
rationale we have left it unstructured. Use of predefined schemata could limit
the possibilities of information gathering, since there are not many studies on
method rationale (Jarke et al. 1994, Oinas-Kukkonen 1996).
FIGURE 5-4 An example of method rationale for a
‘group’ property type.
This detailed example also reveals the gap between
currently proposed ME criteria and their linkages to detailed metamodels: none
of them support relating situational requirements to individual types or
constraints of a method. Some of the ME approaches (e.g. Heym 1993, Harmsen
1997), however, support relating information about method use situations and
contingencies to metamodels based on predefined schemata. For example, Heym and
Österle (1992) collect experiences in terms of the focus of the method
(e.g. project management, risk management, IS development), application type
(e.g. expert, office or real-time system), and phase of the ISD life-cycle (e.g.
analysis, maintenance). A similar approach is followed in MEL (Harmsen 1997).
These approaches, however, do not explain how these more detailed descriptions
are obtained, nor are they related to detailed metamodels.
The use of method rationale in incremental method
evaluation necessitates that more detailed construction explanations are related
to metamodels, instead of referring solely to ME criteria. It helps in
understanding the effects of method modifications: what capabilities are lost
from the original method if a method element is removed or changed. It also
makes possible argumentation about possible new method types.
Method users can understand method rationale differently.
For them method rationale explains why certain types or constraints of the
method are or are not used in models. We calls this method use rationale. The
collection of method use rationale is important because it reduces the
subjective flavor of experiences, makes a decision on method use more explicit,
and allows users to relate their method experiences directly to method
knowledge. This is important, since all experiences are individual, and
therefore can be either supporting or contradictory.
The rationale of method use, however, is not normally
documented and to our knowledge none of the modeling tools allows the capture of
decisions about method use; only decisions about design choices (i.e. design
rationale (Ramesh and Edwards 1993)). Therefore, it is the task of method
engineers to collect the rationale of method use. A similar data collection
approach is followed by Wijers (1991) while eliciting individual
developers’ modeling knowledge. It must be emphasized that Wijer’s
studies are not related to a priori and restrictive method knowledge.
A priori means that methods are not improved. Instead, existing practices
are documented with metamodels. The restrictive method knowledge means that
modeling was not following an “engineered” method in the same sense
as in tool-supported modeling. This means that in Wijer’s study, the
modeler’s own method knowledge was allowed, and in fact intentionally
sought. In our case, the tool ensures that models are always related to modeling
techniques defined and known a priori. Because of a greater
variety in method use, Wijers applied interviews, analysis of developed models,
and think-aloud protocols, and recorded method use with video cameras. This
active participation during method use allowed the discovery of detailed
modeling knowledge and revealed knowledge about the modeling process. Because
active participation is costly and time-consuming it can usually be applied for
only one or a few developers’ modeling experiences at a time. Thus, in a
large scale method development effort where experiences are gathered from
several users the approach is not necessarily cost effective. There, active
participation can be used for inspecting method use among selected users from
different roles (developers, user, managers etc.).
In incremental ME, therefore, the method use rationale is
collected through structured interviews based on the evaluation mechanisms. This
means that method use rationale is not collected completely; only those aspects
which deal with the evaluation mechanisms are covered. In other words, method
use rationale is collected only when it seems to differ from method
engineers’ intentions (i.e. from method construction rationale).
5.3.3 Type-instance matching
The first technique in incremental method engineering,
type-instance matching, is an analysis of method use through the models
developed. Analysis of models typically takes place at the instance level. For
example, metrics are used to analyze system models (e.g. Low and Jeffrey 1990,
IFPUG 1994, Rask et al. 1993) and method metrics are used to analyze metamodels
(e.g. Rossi and Brinkkemper 1996, McLeod 1997). In ME and especially in an
incremental approach, it is important to analyze both levels together: to
compare IS models with metamodels to inspect whether the constructed modeling
technique has been used. According to the metamodeling approach, the types of
the constructed method are described in a metamodel (i.e. IRD definition level,
ISO 1990) and instances of these types are described in models (i.e. IRD level).
Hence the name for this method evaluation and refinement mechanism.
Analysis of intended and actual use of modeling techniques
is similar to seeking differences between prescribed process models and recorded
process models, proposed by Jarke et al. (1994). Some key differences must be
noted between these approaches. For process modes, the traceability model
collecting what has happened is broader than the guidance model defining the
process to be followed. While evaluating the differences between these process
models, it is also important to ensure that the predefined process is actually
followed by developers. In tool-supported modeling, it is not possible to
develop IS models which are not based on the metamodel. As a consequence, while
analyzing type usage through models we can more reliably expect that the
developers have actually used the constructed method (i.e. each instance has a
type definition, cf. Section 3.3.1): the tool ensures that active constraints
are satisfied and informs users about violations of passively checked
constraints.
The close relation between models and metamodels offers
also possibilities to automate data collection, since all the necessary
information about types and instances is available in the repository. Hence, a
metaCASE tool should support queries for both levels simultaneously. This
functionality is not available in external CAME tools which are separated from
method use (i.e. operate only at the IRD definition level). This automation is
especially important while analyzing complex methods, projects which have
developed multiple models, and projects which have multiple developers. The last
of these is important because it helps highlight differences between people and
reveal their modeling preferences.
Type-instance matching can be performed in two phases:
first by focusing on the usage of basic types, and second by analyzing related
constraints. Both of these are discussed in the following
subsections.
5.3.3.1 Usage of types
To investigate the usage of types, we must collect data about
whether each type of a method (e.g. object types, relationship types, or
property types) is or is not used. The data collection can be fully automated by
inspecting instances according to the types. This approach does not
automatically lead to a method modification, because the number of instances
that a type has does not by itself explain the relevance of a type. Moreover,
because the analysis can suggest alternative modifications the results of type
use must be clarified by interviewing method users after the preliminary
analysis has been made.
Because models are always based on metamodels, three
alternative modifications to methods are possible while inspecting the usage of
types. These are 1) remove types which are not used, 2) divide, or specialize
types which refer to different kind of instances, and 3) combine, or define
linkages between types which refer to similar or related instances. These
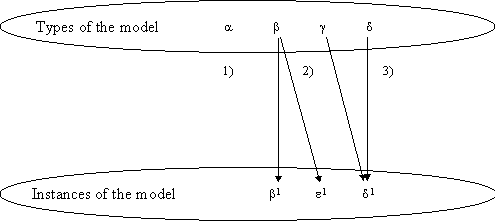
alternative refinement options are illustrated in Figure 5-5 with corresponding
numbers.
FIGURE 5-5 Alternative method refinements while analyzing
usage of types.
The upper ellipse refers to a set of types of a method
(i.e. instances in a metamodel), such as α, β, γ, δ. The
lower ellipse describes instances of a model, such as
β1,ε1,δ1. The mapping between
these levels follows the IRDS framework discussed in Section 3.3.1. Reading from
the top, models are always created based on type level information. Reading from
the bottom, models are always read and interpreted based on the types and their
representations.
1) Remove unused types. Inspection of unused types
is relatively straightforward. Types which are not used at all or have few
instances may be irrelevant in the modeled domain and can be removed or combined
with other types. This means that a method has a redundancy of modeling
constructs, or that not all constructs were relevant in this modeling situation,
or that the method users are insufficiently trained to make adequate
distinctions. A method can also have unused types if all proposed types or
constraints can not be found from the object system, or they are not considered
cost-effective to model (e.g. because they are labor-intensive to
identify).
Checking for unused types is important in simplifying
methods. Similarly, organizations which have adapted external methods often
simplify them radically (e.g. Jaaksi 1997). Especially in cases where local
versions are made for the first time there is a risk of ambitiously modeling
“everything” for incorporation into a metamodel.
2) Division or subtyping of types is required if
the same type refers to different kinds of instances. This means that modeling
constructs are overloaded and new types, constraints, and related
representations are needed. For example, specification of classes which are
persistent (e.g. MOSES, Henderson-Sellers and Edwards 1994) and at the same time
deal with application interfaces (e.g. UML, Booch and Rumbaugh 1995) is not
possible according to any of the object-oriented methods analyzed in Chapter 4.
To capture both of these characteristics, additional instance-based information
must be specified. Although the analysis is based on semantics, and therefore
can not be evaluated solely by analyzing models separately from the real-world,
some pointers to this kind of need can be found from models:
| - | Method
users may extend modeling techniques by using different naming policies for
instances. This kind of modification is a common form of tacit, on-the-fly
modifications (Wijers 1991). An example of such an extension is to name similar
instances with a specific suffix indicating the similarity. Naming extensions
used can be also found from a data dictionary, or from a documentation property
type.
|
| - | Instances
of the same type which are based on different wording (e.g. nouns versus verbs,
or singular versus plural), or use of other distinctions (e.g. capital and lower
case letters) may indicate that a single type is inadequate to differentiate
instances.
|
| - | Instances
based on different wording can be further analyzed based on the property types
used. An overload of modeling constructs can occur if instances of the same
non-property type have instances with different property types. For example, in
the case of relationships, a flow which is named with a verb and described with
parameters can indicate that the flow represents a function, a procedure, or an
operation. In contrast, a flow which is named with a noun may indicate only data
passing. These different kinds of flows could also be distinguished at the type
level (e.g. relationship types for an operation and a data flow). In the case of
object types, we can analyze differences between the relationship types the
object type instances participate in. If objects of different wording
participate in different relationship types they may denote different object
types. |
The resulting refinements can be carried out either by
introducing a new non-property type, or by using a characterizing property type.
A new non-property type is required if instances of a non-property type have
different properties or constraints, e.g. a different type multiplicity. If the
only type level difference is the need to classify instances then a
characterizing property type is sufficient. Depending on the tool support,
different representations may require new types. If the representation of a type
can be changed based on instance information (e.g. depending on the value of a
property) the creation of new types for notational reasons is not
required.
3) Combinations of types, or definitions of linkages
between types are required when there is redundancy among modeling
constructs, i.e. a method has several instances of different types which refer
to the same real-world or semantic entity. The use of several types that refer
to the same thing is not always undesirable because it allows one to inspect an
object system from different perspectives, and thereby to integrate techniques.
Similarly, the metamodels developed in Chapter 4 show that the use of different
types to specify the same instance information is relatively common. For
example, in some situations an external entity in a context diagram (like in
Yourdon 1989a) can correspond to an entity in an ER diagram (Wijers 1991, p
171). In other situations only data stores of a data flow diagram can be
specified as entities. Redundancy of types in a single modeling technique,
however, is not considered desirable, because it makes modeling time-consuming
by introducing additional complexity (Weber and Zheng 1996).
Some linkages are already defined in a constructed method,
but we are interested in finding linkages which are not defined and could be
included into a method. These can be found by analyzing:
| - | Instances
which include the same values as their properties can indicate interrelations.
Especially if values are shared among identifying property types, type level
linkages could be defined. This refinement supports the maintainability of
models and enables consistency checking (cf. Section
5.3.4.2). |
| - | Instances
which are nouns, verbs, or adverbs formed from the same root word, and which
belong to different types can indicate some kind of relation at the type level.
Also, synonyms can indicate that different users apply different modeling
constructs to describe the same instances. The wording and possible synonyms can
be inspected from the data dictionary related to models and by interviewing
different developers about their naming
policy. |
| - | Instances
of object types can furthermore be analyzed based on the relationships they
participate in. If instances of different object types which are named similarly
(i.e. same wording, synonyms) participate in similar relationship type instances
they probably denote the same instance. A similar approach is often the only way
to find out the class which a specific state in a state model describes: if a
transition to a state includes actions which the same class includes as its
operations, the state describes a part of the life-cycle of that class’s
objects[26]. |
The resulting refinements can be carried out either by
combining types or by defining constraints which allow instances to be linked. A
combination of types is not applicable if the non-property types have different
property types, participate in different relationships types, or have different
constraints. It is also possible to have different types which share exactly the
same property types, constraints, and participate in the same relationship
types. For example, in Coad and Yourdon (1991a) the only differences between
classes and class-&-objects are their semantics (i.e. class is an abstract
class as it does not instances) and representations (i.e. single lined rectangle
for a class, double-lined rectangle for classes with instances).
A more detailed analysis of these refinements would
require that method use is inspected in relation to other types and to more
detailed constraints of the method. Accordingly, most of the modifications deal
with refinement of method knowledge at the level of
constraints.
5.3.3.2 Usage of constraints
Evaluating the usage of constraints is concerned with
inspecting how the rules of the modeling techniques were applied. It extends the
analysis from types to constraints. As with the type usage, the inspection of
constraints can lead to the removal or addition of constraints: Some of the
constraints defined may have been too strict, or conversely some might not have
been used at all.
Data collection on the use of constraints is performed on
the basis of the constraints described in the metamodel. In the following we
describe what constraints need to be checked based on the essential constructs
of metamodeling (see Chapter 4.4). Basically, most of the constraints used in a
single technique are straightforward to analyze, whereas constraints related to
integrating techniques are more complex. Below we discuss each constraint and
the method refinements that can be suggested on the basis of its
usage.
1) Identifying property. Properties which have
inconsequential or dummy values are not applicable for identifiers. Accordingly,
the identity constraint can be removed, and perhaps another identifying property
type or types defined in its place. It must be noted that the identity does not
deal with identity in a repository, but rather identity among design
information. This is only meaningful for humans, since computer-aided modeling
tools normally use internal identifiers (see also Section 4.4.1.1). New
candidate identifiers can be found from other property type values. For example,
instances in a dictionary property type can reveal candidate
identifiers.
2) Unique property. Values of property types which
are slightly changed or are based on different wording (because the tool does
not allow the same instance values) may denote that the uniqueness constraint is
limiting modeling in the defined scope of the constraint. The scope of the
constraint can be refined to include a smaller set of values, for example from
all instances of a given property type to instances in a single model, or the
whole uniqueness constraint can be removed. In contrast, if different instances
of the same type can not be distinguished, compared, or checked adequately a
uniqueness constraint needs to be added.
3) Mandatory property. As with identifiers, a large
number of dummy values added to satisfy the mandatory constraint should lead to
its removal. Alternatively, property types which always have values may indicate
that the property type should be defined to be mandatory.
4) Data type of properties. Although tools normally
ensure that data types are followed, the use of complicated data types, default
values, and predefined values can be analyzed. Property types which allow free
form text can include definitions which should follow a certain structure or
syntax (like CATWOE discussed in Section 5.2.3). These can be added as new
property types, or alternatively a syntax could be defined for a property type.
A default value and predefined values can be modified to
speed up modeling. A default value can be changed if another value is more
commonly used. For property types with a mandatory constraint the most used
value is declared as the default. Also predefined values which guide selection,
such as stereotypes or multiplicity values (e.g. Booch et al. 1996), and which
are not used may be removed: they slow down modeling and make use of the method
more complicated.
5) Cardinality defines whether instances of a
relationship type are binary or a specific n-ary. Because all possible
alternatives of participating roles and objects do not necessarily appear, nor
are all cardinality values used, the refinement possibilities of the cardinality
constraint can not be studied fully by analyzing models.
Some aspects, however, can be analyzed from model data. If
only binary relationships are allowed the need for an n-ary relationship can be
recognized when multiple relationships with the same property values are created
for the same object. For example, an inheritance relationship defined as binary
will need to be defined as n-ary if a class participates in several
relationships in the superclass role and with the same discriminator value. This
requires a change to the maximum cardinality constraint. The minimum constraint
can be changed to one if all instances of a given relationship type use the
specified role type, i.e. changing an optional role to be mandatory.
If n-ary relationships are not used the cardinality
constraint can be removed. Another option would be to create a specific
relationship type for n-ary cases, as in OMT (Rumbaugh et al. 1991). More
detailed refinements, like n-ary relationships only being used for specific
instances of an object type or specific cardinality values, must be carried out
together with method stakeholders.
6) Multiplicity constraints deal with the number of
role type instances an object type instance may have in a model. The constraint
can be bound either to instances of a single role type, or to instances of
different role types. As with the evaluation of cardinality constraint, not all
multiplicity alternatives are necessarily applied during modeling and therefore
their suitability can not be analyzed solely from model data. The following
principles, however, help identify refinement possibilities:
| - | Existence
of role type instances for all object type instances may indicate that the role
type should be defined to be mandatory, i.e. minimum multiplicity should be one.
|
| - | Existence
of only one instance of a role type for each object type instance indicates a
one-to-one constraint value (1,1). Alternatively, a passive checking for a
maximum value could be used to define that an object should only have one role
type instance: in some cases, which the users should be informed about, multiple
roles would still be possible. An example of such a case is a recommendation to
use single inheritance (i.e. each class only participates once in a subclass
role). This option is also relevant for instances of several role
types. |
| - | Role
types which are defined as mandatory and have “unnecessary”
instances may be made optional (i.e. minimum multiplicity of zero). Examples of
unnecessary instances are roles and related relationships which are not
specified with property values. Changes to the checking mode are not relevant
here because both modes are possible only for the maximum multiplicity.
Similarly, it must be noted that role types which are not used at all have
already been inspected through the type usage
analysis. |
7) Cyclic relationships. Analysis of cyclic
relationships based on model data can only lead to removing cyclic
relationships. If cyclic relationships are not allowed, but required, this
implies that not all aspects of the object system can be represented. Additional
objects to overcome the prohibited cyclic relationships could be analyzed, but
this would require semantic analysis.
8) Multiplicity of types. If system models are
scattered into multiple small models, a minimum constraint can be applied to
remind users, but not to ensure (because of the passive checking mode, cf.
4.4.1.9), that instances should be combined into smaller number of models.
Alternatively, the creation of large and overly complex models can be prevented
(with active checking), or discouraged (with passive checking) by setting the
maximum multiplicity constraint for selected object types. The multiplicity of
types is related to complexity management which can also be supported with other
metamodel-based constraints, e.g. complex objects, explosions, and
polymorphism.
9) Inclusion. In contrast to analyzing all
instances of a type, an analysis of inclusion means that instances are analyzed
inside a single modeling technique. For example, a ‘library class’
(Henderson-Sellers and Edwards 1994) can be useful in a specific modeling
technique but not in all techniques, or vice versa. In addition to the use of
non-property types, the occurrence of their property type instances needs to be
analyzed since it is typical, at least in the methods analyzed (Chapter 4), that
not all information on the same non-property type is required in different
modeling techniques. For example, in the metamodel of UML (Section 4.4.3) an
‘object’ can be used both in a class diagram and in an object
diagram with a property type ‘values’. This property type is used to
describe instances of attributes of a class, but it is not necessarily relevant
in class diagrams but only in object diagrams. This reveals polymorphism and is
analyzed through the polymorphism constraint below.
10) Complex objects deal with an abstraction
mechanism which allows the modeler to build aggregate-component structures.
Based on the usage of complex objects, the most straightforward method is to
determine which are not applied and remove them as inapplicable. A more detailed
analysis necessitates that different characteristics of the complex object type
are examined.
| - | A
component type can be declared dependent if all instances of a component type
occur in complex
objects. |
| - | A
component can be declared mandatory if all aggregate objects have instances of
the component type.
|
| - | A
component type can be declared exclusive if none of its instances belong to
other complex objects.
|
| - | A
component type is shared if the same instances of the component type belong to
several complex objects.
|
| - | A
constraint for aggregated relationships can be defined when all relationships of
the components outside the complex object are also defined for the aggregate.
Whilst the constraint is undefined there exist redundant modeling tasks in order
to maintain consistency (cf. Section
5.3.4.2). |
It must be noted that not all dimensions of complex
objects (cf. Table 4-4) are analyzed because they are not relevant, or can not
be analyzed from model data. For example, connected components and relationships
of an aggregate can be analyzed with a multiplicity constraint. The limited use
of complex objects can also be a consequence of the “dictatorship”
of a tool. For example, aggregate object types may remain unused because they
have mandatory components which are not applicable in the modeled domain. Hence,
the constraints of the complex object could be checked passively, although our
analysis of complex objects suggested that they can always be checked actively.
Passive checking would allow violation of the constraints of complex objects but
would still inform the method user about the inconsistencies.
11) The explosion constraint deals with organizing
and structuring multiple models. The original metamodel can either ensure (with
active checking) or encourage (with passive checking) the use of explosions.
While analyzing the current usage of the explosion constraint, the following
situations indicate a need for modifications:
| - | Explosion
structures which are not used may be irrelevant and removed. Alternatively, the
active checking which specified explosion structures as mandatory may be the
reason why they are not used: passive checking could be applied
instead. |
| - | Explosions
should be defined as mandatory if all instances of a specific type (i.e. a
source) or a technique (i.e. a target) participate in explosion structures. A
mandatory explosion structure is defined with a minimum cardinality value of
one, or alternatively if only one explosion exists with a minimum-maximum pair
of (1,1).
|
| - | Passive
checking can be applied if an explosion structure is not used for all instances
of a source type or a target technique. The use of active checking can not be
analyzed from the resulting models because it deals with the modeling processes,
i.e. whether all explosion structures were created in a top-down or in a
bottom-up manner. This would be possible in modeling environments which allow
queries on instance creation times.
|
| - | A
constraint of a shared explosion target could be removed if only one instance of
a source type refers to a model.
|
| - | A
constraint of an exclusive target model can be considered too restrictive if it
leads to the creation of multiple models which have fewer instances, or which
have multiple shared instances. The former can be partly analyzed by inspecting
the multiplicity of types in models, and the latter by inspecting the occurrence
of the same instance
values. |
| - | A
model scope constraint is inaccurate if the same instance has the same explosion
links in multiple models. For example, a class has the same life-cycle, i.e. an
explosion to the same state model, although it is represented in different
models. Hence, the method scope should be
used. |
12) Polymorphism means two or more types sharing
the same property values. The evaluation deals with analyzing polymorphism
structures which are not used and by seeking instances which can indicate
polymorphism. Based on the former option, polymorphism structures which are not
used may not be suitable for the modeled domain. It must be noted that not all
structures of polymorphism are necessarily described by sharing property values.
Instead other constraints of a modeling technique can be used for this purpose.
For example, an object can have both an ‘instantiation’ relationship
type to a class and an object can be identified by a property type ‘class
name’ (e.g. in Booch and Rumbaugh 1995).
Based on the latter option, new polymorphism structures
can be defined to support reuse. These linkages are typical between different
techniques where no clear representation for linking is available. First, the
analysis is carried out by seeking values among different property types which
are based on the same wording, suffix, etc. This results in a set of types which
describe the same model data. This approach is similar to analyzing overloading
of modeling constructs with type usage (Section 5.3.3.1). For example, as in the
metamodeling example in Section 3.3.3, values for actions in a state diagram and
values for operations in a class diagram are the same.
Second, a number of types participating in a polymorphism
structure must be inspected. For example, a value “add customer” can
be used as an instance of an ‘operation name’, an ‘action
name’ and a ‘message name’. This means that the three types
share the same value. Third, the size of a polymorphism unit must be analyzed,
i.e. how many instances of different property types are shared together. For
example, actions and operations typically share only instances of the naming
property types since actions do not include operation-related characteristics,
like parameters or access levels. Also, parameters of a message in an event
diagram (Rumbaugh et al. 1991, Booch et al. 1996) are the same as operations.
Hence, the values shared include both the name and parameters. This is
illustrated in Figure 5-6. An action, an operation and a message denote the same
instance values. In a state model, actions are defined with a name, but
operations of a class also include parameters and access levels, e.g. public. A
sequence property type is only meaningful for messages in a message
diagram.
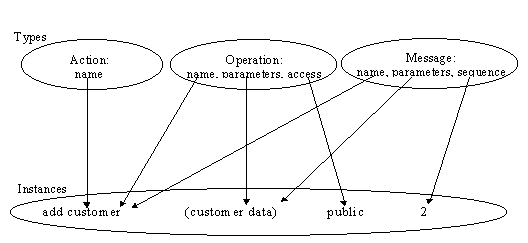
FIGURE 5-6 An example of polymorphism structure.
Fourth, dependency among polymorphism structures requires
that the modeling process be analyzed. This would allow us to find the types for
which the shared instance values were first defined. For example, candidate
operations should be added first into a message diagram and therefore operations
of the class should refer primarily to already defined messages. Although
analysis of dependencies deals with the modeling process, some of them can be
recognized from model data. If a property type always has a value used in
another property type, the former type may be dependent. Alternatively the
checking mode for the dependency can be changed: active checking of dependency
is required if models need to fulfill the rule at all times, and passive
checking is used for an optional dependency.
Finally, the scope of a polymorphism can be changed if
shared instances belong to a smaller scope than originally intended.
Alternatively, if polymorphism is not used, because the instances the user
wanted to refer to were outside the permitted scope, a larger scope could be
specified.
5.3.4 Modeling the object system
The second approach to incremental ME is analyzing modeling
capabilities. Tool-supported modeling capabilities are divided into abstraction
and consistency checking (Olle et al. 1991, see also Section 2.3.2). The former
means the capability to describe relevant aspects of object systems, and the
latter means the capability to maintain consistent models.
The evaluation of modeling capabilities requires
information about the object systems modeled and thus extends evaluation from
the IRD level into the application level of IRDS (cf. Section 3.3.1). As a
result, the evaluation must be conducted in close cooperation with method
stakeholders. This means interviewing stakeholders in addition to analyzing
model data. Interviewing is used to collect opinions on the method use and
requests to change the method. The evaluation questions described below focus on
structured interviewing.
5.3.4.1 Abstraction support
A conceptual structure behind modeling techniques suggests an
abstraction to describe an object system (cf. shell model, Figure 2-2). An
abstraction means perceiving some aspects of the object system while ignoring
other aspects. Two issues must be noticed while evaluating tool-supported
abstraction capabilities. First, a tool provides a set of concepts which are
limited from a syntactic and a semantic point of view. Therefore,
non-diagramming concepts
[27] (Wijers 1991) or
other additional concepts can not be applied. Although a tool can include
free-form modeling techniques, they are not adapted
a priori to the
situations and therefore their evaluation is excluded here (for this type of
analysis see Wijers 1991). Second, not all aspects of the object system are
necessarily represented in a similar notation to that used in paper documents
because a CASE tool uses dialogs, linkages between models (e.g. an explosion
structure), and a data dictionary to capture specifications.
The evaluation of abstraction support can be analyzed by
examining how object systems could be represented, by analyzing difficulties in
making representations, and by inspecting differences among method users. These
are described below:
1) Are all relevant aspects of the object system
perceived with the method? The limitation of abstraction support can be
recognized when some aspects of the object system can not be perceived and
represented with the modeling techniques. This requirement sets out the goal
that the method must capture essential “objects” of the design
problem and convey relevant information about them. As the review of method
evaluation studies showed, this is the most common approach (e.g. Schipper and
Joosten 1996, Wijers 1991, Fitzgerald 1991). Based on the evaluation,
refinements can be made by:
| - | Adding
new types which illustrate aspects to be modeled. These can include a new
non-property type (e.g. an object type which has property types and other
constraints) (e.g. Jaaksi 1997), several types, or a whole modeling technique
(e.g. Tollow
1996). |
| - | Adding
a new property type (or types) that characterizes currently used non-property
types (e.g. for subtyping entities, as in Wijers
(1991)). |
| - | Adding
new relationship (or role) types for describing specialized connections between
objects. |
| - | Removing
constraints which restrict abstraction. Examples of possibly restrictive
constraints are multiplicity constraints (limiting the number of relationships
which an object type instance can participate in) and cardinality (limiting the
number of roles a relationship can
have). |
2) What types have been difficult to use?
Difficulties in making abstractions can indicate that the method does not
“fit” the object system, or has not been introduced and taught well.
If the difficulties are related to an inappropriate method, its conceptual
structure can be redefined.
3) What types have been used differently among
individual developers? Differences in method use can be due to individual
differences and modeling preferences. For example, some developers can use state
models to describe an object’s life-cycle as the method engineer intended,
whereas others can use them for interface design (e.g. Jaaksi 1997). Similarly,
method developers can have different requirements from end-users (Tolvanen and
Lyytinen 1993). Although individual differences of method use exist (e.g. Wijers
1991, Hofstede and Verhoef 1996) and can be supported through ME, ISD is a group
activity. The modeling results should be based on a common understanding of
modeling concepts. This is important for communication, minimizing
misunderstanding etc. Hence, method refinement should strive to find linkages
between related views of method users (Nuseibah et al. 1996).
5.3.4.2 Checking support
Problems of insufficient computing power are most noticeable
in ensuring the consistency of models. Use of checking related constraints in
the metamodel will result in well-defined and complete model instances.
Consistency checking supports the maintainability of models, decreases the
redundancy of modeling tasks, and supports traceability by informing of
side-effects of changes. These emphasize both vertical and dynamic integration
of conceptual method connections. The checking support is emphasized in ISD
efforts where multiple models are developed with different techniques
(integration among techniques or methods) and by different people (coordination
among method users).
With respect to metamodel data, checking can be carried
out either actively or passively. Active checking ensures that models
continuously satisfy the constraints of the metamodel, whereas passive checking
requires a modeler’s attention. In modeling tools passive checking is
typically implemented with checking reports which inform method users about
violations.
Although consistency is checked with various algorithms it
is always dependent on the underlying metamodel data. Checking support can be
evaluated with the following questions:
1) Are the developed models consistent? This
question can be partly analyzed by checking if the models satisfy both the
active and passive checking rules defined in the metamodel. Active checking is
already ensured by the tool and passive checking can be analyzed by running the
consistency reports made during the tool adaptation. If models are not
consistent, either consistency rules are not applicable or they are not used. In
the former case the checking related constraints can be removed, and in the
latter case active checking can be required.
2) Is manual work required to keep models
consistent? This question deals with finding new constraints to maintain
consistent models. Redundancy of modeling occurs when the same instance
information must be changed several times in order to maintain consistent
models. This error-prone and time-consuming task can be reduced by adding
constraints to the metamodel and by providing new checking reports based on the
constraints added. Also, difficulties in tracing how changes in one model affect
specifications elsewhere can indicate a need for new constraints. Redundant work
exists in the following situations:
| - | The
addition of an instance requires the addition of the same information elsewhere
in the models. For example, creation of a new action in a state diagram
necessitates that the action is specified among operations of a class (cf.
metamodeling example in Section 3.3.3). This situation would require that the
action names are dependent on the operation
names. |
| - | A
change to an instance requires that other instances must be updated. For
example, a change of an entity name must be reflected in a data dictionary and
in data flow diagrams (Yourdon
1989a). |
| - | The
deletion of design data requires searching and removing the same instance
information. For example, the deletion of a class might require the manual
deletion of related state models or removal of individual states. The former
could be automated by defining a minimum cardinality of one for the explosion
target (i.e. the state model), and the latter by using dependent polymorphism
among states and classes (i.e. each state must refer to and be dependent on a
class through its name, as in UML (Booch et al.
1996)). |
Some refinements can be carried out by changing the
checking mode, or the scope of the constraints. Active checking can be used for
constraints which are defined but not applied or when the use of passive
checking is considered tedious. The scope of the consistency related metamodel
constructs can be changed if consistency is not ensured among instances outside
the defined scope: the scope is refined from a smaller set of instances (e.g.
dependent type) to include a larger number of instances (e.g. model or method).
5.3.5 Supporting problem solving
Methods are not only used to describe a current situation but
also to carry out a change process with respect to object systems. This
necessitates that a method supports the seeking of candidate solutions and
deciding amongst them (Tolvanen and Lyytinen 1994). Both of these can be
supported by a CASE tool with form conversion and production of documents (Olle
at al. 1991, cf. Section 2.3.2). Form conversion provides mechanisms to seek
alternative solutions by manipulating design data according to method knowledge
(i.e. according to the conceptual structure or the notation). Deciding among
solutions can not be directly automated but can be supported through the
provision of documents for review and comparing candidate designs with the
current configuration.
The evaluation of problem-solving capabilities is not much
addressed as most approaches (cf. Section 5.2) focus mainly on modeling support.
One reason for this focus is the evaluation of methods separate from their use
situation. The analysis of problem solving capabilities reveals which parts of
the method knowledge are required to seek alternative solutions and which are
needed only for abstraction and checking. For example, while generating code
from object-oriented methods, not all concepts of the method are needed:
although message diagrams are important in understanding object interaction,
they are not required since the design data related to program code is already
represented in class diagrams.
As with the evaluation of modeling support, the evaluation
of a method’s role in problem solving requires the participation of
stakeholders. It involves an inspection of the application level to refine the
IRD definition level (i.e. metamodels); in other words, a comparison of
development outcomes and the method’s role in producing them.
5.3.5.1 Support for form conversion
Form conversion in a CASE tool means an analysis and a
comparison of design data, simulation, generation of program code, and building
of prototypes. Like consistency checking, form conversions are carried out by
algorithms (e.g. checking reports or transformations) but they are only possible
if the metamodel specifies and maintains the necessary design data. This means
that aspects other than those found directly from or derivable from models can
not be converted. In other words, conversions are largely dictated by the
abstraction capabilities. Naturally, method knowledge is also included in the
conversion algorithm (e.g. the syntax of the generated language), or can be
added by developers during the conversion (e.g. a choice among approaches to
convert an inheritance into a relational model, see Rumbaugh et al.
(1991)).
The evaluation of method support deals with analyzing how
well it provides concepts and notations for form conversions. A conversion of
conceptual design data takes place, for example, when a schema for a database is
generated. Conversion of representational data occurs when the conceptual design
data remains the same but the notation changes. For example, BSP (IBM 1984)
determines boundaries between ISs by organizing the data classes and business
processes into a matrix so that a minimal number of connections occur among ISs.
During this conversion only representations of data classes and business
processes are clustered according to the use of data. Form conversion
capabilities can be evaluated with the following questions:
1) Can the required analysis be made using the models?
Although analysis of models is dictated by the rationale that suggests
modeling concepts, model analysis can reveal the need for new concepts. For
example, during workflow modeling, a demand to analyze bottlenecks may arise.
This, however, is impossible if the models do not capture information about
capacity and throughput times. This suggests additions of property types to the
workflow modeling technique. Similarly, inspection of encapsulation requires
that attributes and operations of a class can both be specified directly with
the specification of a class (e.g. Rumbaugh et al. 1991), or in a class related
models (e.g. Coleman et al. 1994).
2) Can alternative design solutions be generated from
models? A method should include rules which allow the conversion of models
into various design alternatives by using the metamodel data. For example, to
generate alternative solutions based on the level of (de-)centralization of the
organization, the method should describe organizational structures. Similarly,
interaction scenarios between classes can be examined by describing a
significance for events (e.g. Awad et al. 1996).
3) Does the design satisfy requirements of later phases
or external tools? An outcome of modeling is a design solution which can be
implemented or further analyzed with other methods or external tools (e.g. with
a simulator, a programming environment, a code generator, or a reporting tool).
Therefore, vertical integration with other tools and methods (cf. Table 2-2)
must be provided. In other words, the requirements of later phases must be
satisfied to provide an integrated method. For example, although UML (Booch et
al. 1996) supports the generation of CORBA IDL interfaces (Iona 1997) better
than other methods analyzed in Chapter 4, its support is not complete. As an
example, UML does not consider context clauses for IDL operations. Hence, the
UML metamodel can be extended with property types for context expression.
Metamodel extensions towards programming languages are further discussed in
Hillegersberg (1997).
The analysis of form conversion capabilities typically
leads to extending the conceptual structure with new types and constraints. If a
conversion suffers from unavailable design data, for example because modeling
tasks can not be completed unless instance values are added to the models made
earlier, constraints can be added. These include a mandatory constraint for
property types, multiplicity of types, and multiplicity of roles. In addition to
changes to a metamodel, changes are also required in form conversion
algorithms.
5.3.5.2 Support for review
Information system specifications which can be understood and
reviewed by stakeholders are of great importance for validation. Tool support
for review consists of the provision of information for stakeholders, such as
summary reports for managers, less formal descriptions of the selected domain
for end-users, and formal specifications for programmers. The documents produced
can vary based on the conceptual data and their representations. Since a review
is always dictated by what is abstracted, the evaluation of review support deals
mostly with representational issues. Tool support for the review step can be
analyzed with the following questions:
1) Can validation of IS models be supported? The
metamodel must help to validate the system descriptions in relation to
stakeholders’ desires and needs. This requirement is partly overlapping
with the consistency criterion. There is, however, a marked difference: validity
deals mostly with the semantic adequacy, whereas consistency focuses mainly on
the syntactic properties of the models. Therefore, validity can not be assessed
by exploring the metamodel alone, but method users can provide information about
which concepts and representations they find useful in validation.
2) Does the method correspond to users’ natural
concepts? Development methods are developed to satisfy developers’
cognitive needs related to design tasks. Therefore, it would be an advantage if
methods were similar to users’ existing concepts and patterns of thought.
For example, Olle et al. (1991) suggests different graphic representations for
different types of users: experts from different areas of the object system may
require different concepts from those employed in the underlying techniques.
Similarly, less formal notations and icons can be applied.
The analysis of review support typically leads to
extending the method in terms of providing different notational constructs, and
simplifying the method for different use
situations.
5.3.6 Remarks on the a posteriori mechanisms
In this section we have put forward mechanisms for evaluating
methods in a given situation. These mechanisms refine a method by adding,
changing, and removing parts of the method knowledge. In other words, they
evaluate which parts of the modeling techniques need to be simplified or
extended. If the mechanism reveals requirements to change the method, it means
that the constructed method may not be applicable in a use situation. The
mechanisms are summarized in Table 5-4. The steps of incremental ME, i.e.
collection of experiences, analysis, and outcome of refinements, form the
vertical axis, and the a posteriori mechanisms the horizontal
axis.
TABLE 5-4 Mechanism for method evaluation and
refinement.
As the proposed mechanisms show, we emphasize modeling and
problem-solving capabilities. They are mostly used in cases of local method
development (cf. Section 2.4.2) and in the method evaluation literature (cf.
Section 5.2), and they can be related to detailed method knowledge. Neither
contingencies nor stakeholders’ values imply modifications of detailed
metamodels, although some changes in contingencies or value-based ME criteria
could be accommodated in a metamodel.
It must be noted that the preceding mechanisms are not the
only ones possible for evaluating methods. They are relevant for our research
question of supporting method improvement through metamodels. The collection and
analysis of experiences, as well as method refinements, are carried out through
the metamodeling constructs. These organize the experience gathering and make
method modifications more explicit and formal. The matching of types and their
instances mostly leads to purging of method knowledge, because extensions which
enlarge the metamodel are not possible. In other words, analysis of the use of a
method in a tool can only show things which the tool has not prohibited. In
contrast, the evaluation of modeling support and problem solving capabilities
mostly lead to extensions of method knowledge. Extensions are largely a result
of method users’ requests which arise from the application level. This
also means that a posteriori ME requires the participation of the method
engineer in ISD to obtain application level knowledge. This supports the claims
that a method engineer must be one of the stakeholders of ISD, such as a project
manager (Odell 1996).
Because the mechanisms are overlapping, they can suggest
conflicting modifications. For example, an analysis of explosion structures can
show that each instance must be exploded, but the analysis of type multiplicity
reveals that resulting models have only a few instances. As a result, the choice
of an appropriate refinement must be made together with method users. Moreover,
neither the mechanism nor the refinements should be prioritized. Therefore, the
preferences of stakeholders can emphasize different mechanisms and resulting
refinements. For example, Hofstede and Verhoef (1996) propose to be less
ambitious with regard to the level of consistency and promote simple
representations (i.e. a small number of graphical symbols).
[26] The state could also
belong to superclasses. The analysis can be further improved by analyzing
neighboring instances. For example, if the transition occurs from a state of
another class the operation should be defined as public (e.g. Booch et al.
1996).
[27] Non-diagramming
concepts refer in Wijer’s (1991, p. 170) study to additions to the
modeling technique which are made when all aspects of object systems could not
be explicitly specified with the modeling technique. Examples of such concepts
in his study include a ‘problem’ and an ‘external
party’.