5.2 Evaluating the applicability of modeling techniques
In this section we shall analyze some proposed approaches and
their weaknesses in evaluating ISD methods. Most research on methods is based on
the assumption of applicable methods. ME research is no exception: otherwise ME
principles would not be proposed. ME research includes, however, one major
difference to most method research, namely the situational dependency. Whilst
method developers often aim to prove the general applicability of methods, ME
research is interested in improving the method use in given circumstances. We
examine method applicability based on the situation in which it is applied. This
is also emphasized in our re-evaluation of method use (cf. Section 2.5.1).
Similar definitions are also proposed by Fitzgerald (1991) as an
“applicability to the case or circumstances”, by Schipper and
Joosten (1996) as “serving in the intended purpose”, and by
Kitchenham et al. (1995) as focusing on specific cases in which a method is
used.
Our focus is on studies which address the applicability of
modeling techniques. First, we shall analyze which kind of approaches the
developers of text-book methods have applied for validating their methods, and
what validation approaches are proposed for situational methods. The former
covers evaluation of methods in general and the latter focuses on evaluating
methods in their use situations. Our interest is in approaches which can be used
to collect, analyze and apply experiences to refine methods. This means that the
evaluation approach should not only analyze whether and how a method has met the
applicability requirements, but also how it could be improved. Therefore, the
analysis does not include approaches which are not linked to evaluating method
knowledge or which do not offer opportunities for method improvements, such as
Kitchenham et al. (1995) and Jayaratna (1994). Second, we acknowledge some key
problems related to method evaluation. Some of these problems are partly solved
with the systematic ME principles proposed.
5.2.1 Evaluation and validation of text-book methods
The applicability of a method forms a core assumption in all
method development. Most method development efforts, however, do not aim to
validate the proposed method at all. Only a few are in any way proven or
justified for the tasks for which they are promoted (Fitzgerald 1991). As a
result, it is difficult to find how claims made in favor of a particular method
— such as “more expressive, yet cleaner and more uniform ... than
other methods” (Booch et al. 1997, p 15) or “to support a seamless
ISD process, or the reversibility of models” (Walden and Nerson 1995)
— can be proven.
By analyzing methods modeled in Chapter 4 two kinds of
approaches for determining the viability of a method are used: a demonstration
of the method in some imaginary or real-world case, and a comparison with other
methods. Both of these approaches are also widely used in studies comparing and
evaluating methods, e.g. those reported in the CRIS conferences (Olle et al.
1982, 1983). Neither of these approaches, however, can provide strong evidence
for method applicability (Fitzgerald 1991). Demonstration (e.g. Yourdon 1989a,
Booch 1991) describes how one or more ISs are captured into models. The subject
of validation is mostly a modeling technique (i.e. concepts and notations)
rather than the process or design objectives which explain the use of such
models. Little information is given about the background of the cases, such as
contingencies, participants, method users, or alternative solutions. Weaknesses
of the method are not considered or mentioned at all. As a result,
“validation” means here only that the method can be used in
modeling, rather than that it is useful or can lead to better results than other
methods.
The latter, the comparison approach, focuses on
similarities and differences between the proposed method and other similar
methods (e.g. Firesmith et al. 1996, Booch and Rumbaugh 1995). The proposed
method is typically used as a yardstick: little wonder that it is often
described to be more comprehensive than others. The main emphasis in evaluation
is on explaining why the new concepts are required. Here the justification of
the method is normally explained at the type level only, because method use is
not addressed at all. Comparisons thus focus mainly on modeling techniques and
underlying conceptual structures. One reason for focusing on modeling techniques
only is that method books do not usually describe other parts of method
knowledge systematically. As a result, the main argument for a particular method
is based on the endorsement by an authority.
Yet, as is described in method
books
[24], one can state that the best
“proof” for a method is its use: an assessment of a number of ISD
efforts following a method shows its viability. Use of a method’s
popularity as a mechanism to prove its applicability is questionable. First,
based on this strategy certain modeling techniques, like ER diagrams (Chen 1976)
or data flow diagrams (Yourdon 1989a), should be considered to be applicable.
There is, however, a great number of dialects available for these techniques.
Also, criticisms against some of the principles they apply have been raised. The
different versions of the ER model (e.g. Chen 1976, Batani et al. 1992, Teorey
1990) show that no single variant of the ER model is popular. Similarly,
criticisms against the top-down decomposition applied in data flow diagrams has
been presented (e.g. Goldkuhl 1990, Booch and Rumbaugh 1995). For example,
Goldkuhl (1990) claims that top-down refinement of system leads to costly
maintenance of designs and to a loss of information between the different
levels. Second, the low acceptance of methods in general (cf. Section 2.4.1) and
their adaptation in particular (cf. Section 2.4.2) indicates that most methods
as proposed by their developers have failed. Therefore, instead of a general
validation of methods, we are more interested in the validation of methods in a
given situation. This is discussed in the next
section.
5.2.2 Evaluation of methods in the problem context
In our literature review we found only a few studies that
aimed to validate the applicability of methods more systematically. These are
the validation of action modeling by Fitzgerald (1991), and of trigger modeling
by Schipper and Joosten (1996). These can be distinguished from earlier method
evaluations or validation approaches by their use of explicit measurements as a
basis for the evaluation. In the following these approaches are briefly
described by explaining the context in which they are used, what aspect of the
method is evaluated, how data is collected, and what measures are used. Finally,
we describe how the evaluation results are interpreted and applied for method
refinements. The results of this analysis are summarized in Table 5-3.
TABLE 5-3 Summary of validation approaches

Fitzgerald (1991) evaluates the richness of a technique in
terms of what is abstracted, i.e. its modeling power. He starts the evaluation
by describing the objectives and design criteria of the technique. This forms
the basis for the evaluation. He also describes the rationale of the technique
(i.e. why the technique has been constructed as it is). In the evaluation the
modeling technique is related to the larger context of the whole method, but no
clear distinction is made between arguments in favor of the method in general,
and those arguing for the specific modeling technique. The evaluation is carried
out through modeling and trying to find out how well relevant aspects of the
object system could be represented. The main instruments for data collection are
the use of examples from different situations (but nothing is explained of the
type of situations they were (e.g. domain, contingencies)), and why they were
selected as modeling subjects. The results are derived based on the
researchers’ (acting as method users) opinions of the richness and
modeling power of the technique. Thus, the evaluation approach, as noted by the
author, is highly subjective and dependent on the selected modeling situations.
Furthermore, the approach does not present possibilities to refine methods
during or after the evaluation.
Schipper and Joosten’s (1996) contribution to method
evaluation is their proposal and use of multiple evaluation instruments. They
base their approach on reviewing how validation and evaluation of modeling
techniques are studied in other modeling-related areas, and what types of
validity are recognized in the literature. They propose a model of validation
which focuses on observing how the intentions of the method developer, in terms
of associated characteristics of a method, are met. The approach focuses on
evaluating a modeling technique separately from other parts of the method, and
starts by describing the method developer’s intentions (e.g. to allow
modeling of logistic processes) and characteristics (e.g. easy to learn) for the
modeling technique. Next, the rationale for the technique is stated by arguing
how the intentions are met and relating them as characteristics of the modeling
technique. This method construction rationale is derived similarly in Fitzgerald
(1991), but Schipper and Joosten also include characteristics other than those
related to modeling power. Therefore, the instruments for observing the
characteristics are also different. Schipper and Joosten (1996) propose and
emphasize the use of instruments (both qualitative and quantitative) in
validation depending on the type of intentions. Various instruments can be used
simultaneously to check convergent and discriminant validity. The instruments
proposed include a literature study, method metrics, analysis of deliverables,
content analysis of interviews and measurement scales for ease of use and
usefulness. Of these, method metrics (Rossi and Brinkkemper 1996) and ease of
use and usefulness (Davis 1989) are instruments which are not used by Fitzgerald
(1991). A major reason for this difference is that Fitzgerald has carried out
the validation effort by himself, whereas Schipper and Joosten target their
studies to developing an automated method selection procedure in CAME, i.e. to
be used also by people other than the method developer.
The study by Schipper and Joosten, however, does not
describe how the instruments are applied for data collection and analysis, nor
do they provide examples in favor of the evaluated trigger modeling technique.
The result of the validation effort should be the list of intentions and
arguments derived from the observations based on the instruments. To illustrate
the approach some examples are given. A goal to model business processes quickly
can be supported if method metrics show that the method is not complex, or users
consider it effective and quick to use. Because of the use of multiple
instruments the observations made can provide better evidence for how
successfully the method fulfills its developer’s intentions.
Finally, unlike Fitzgerald, Schipper and Joosten allow
method refinements during the validation process to improve the applicability of
the modeling technique. The modifications should, however, ensure earlier
observations and intentions remain the same. Although these conditions are
understandable, since they focus on validating a fixed method, they do not
recognize experience based learning, uniqueness of situations and method
evolution. Accordingly, in the following we shall analyze method evaluation
approaches which accept, or even promote, method
evolution.
5.2.3 Evaluation of methods as a part of a continuous ME process
As discussed in Section 3.2, the evaluation of the
applicability of methods in ME research is dominated by a priori
evaluation occurring in the method construction phase. To our knowledge, only
the learning based approaches to method development (Checkland 1981, Kaasbol
and Smordal 1996, Wood-Harper 1985, Mathiassen et al. 1996) indicate the
importance of experiences and learning from method use as key mechanisms both to
evaluate and to refine methods. Checkland (1981) advocated the learning based
approach to method development and evaluation by introducing a cycle of action
research in which experiences on method use provide the main source for method
modifications; first by using the method and second by learning method use. This
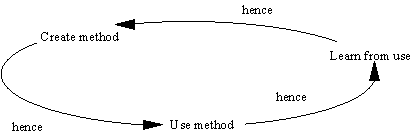
cycle is illustrated in Figure 5-1.
FIGURE 5-1 The evolution of a method through a learning
cycle (Checkland 1981, p 254).
According to this cycle, ME can be viewed as a continuous
and never-ending process, in which experiences are elicited from working with
the method. Checkland has used the action research cycle as a key mechanism to
develop Soft Systems Methodology (SSM) by repeating the cycle in many
development cases and situations. In fact, the cycle for developing SSM began in
1969. The main reason for the cyclic learning based approach seems to be the
difficulty of developing methods into a new field. In the case of SSM this means
development based on methods applied successfully in developing
“hard” systems into methods applicable for soft, human activity
systems. This point also confirms the motivation of the incremental approach to
ME made earlier (Section 5.1.3).
Because the cycle of method evolution is carried out as
action research it is sensitive to the context in which the method is used and
thus situation-bound. Although SSM includes the idea of incremental ME the
objective of the learning cycle has been to develop general or universal
principles for developing human activity systems. In other words, the iterative
cycles have not been used to develop SSM towards situation-specific needs in the
same sense as in the ME literature, but rather towards learning about various
situations in which the SSM is applied. Moreover, Checkland emphasizes that SSM
is not a method in the same sense as defined in this thesis but something
between a philosophy or a framework, and a
method
[25]. However, as Checkland notices, some
parts of SSM are very close to our definition of modeling technique (e.g.
CATWOE). Therefore, from the ME point of view, the learning cycle has been used
to define method knowledge in terms of concepts, processes, assumptions and
values. Because of our interest, we shall focus only on the incremental
development of SSM’s concepts and modeling techniques.
In Checkland’s approach the applicability of a
method is evaluated based on its strength as a working device in a process of
developing human activity systems. As such it applies a general question for the
evaluation: “Was the problem solved” (Checkland 1981, p 192).
However, he does not provide detailed principles of how experiences are
collected (other than case records), analyzed, and applied when starting the
next cycle: i.e. creating or modifying the method. Of course it can be claimed
that such more concrete and systematic principles exist but they are not
reported. In general, the concepts and notations used to develop conceptual
models are not defined and thus not evaluated according to any systematic
principles. The only reported exceptions are the root definition according to
CATWOE and the sequencing between the stages of the method. Especially the
former is relevant for our study, since CATWOE is closest to our definition of a
modeling technique. The applicability of the concepts behind the root definition
(Customer, Actor, Transformation, Weltanschauung, Ownership and Environmental
constraints) were studied by seeking a dozen well formulated root definitions
from earlier projects to test that the concepts behind the mnemonic CATWOE could
be found. As a result of this analysis, they conclude (Smyth and Checkland 1976)
that the CATWOE concepts are relevant because they would speed up the process of
finding root definitions and enrich debates. The sequence of the method’s
tasks is another example of experience based evaluation, although it focuses
more on the process than on modeling techniques. In SSM the transitions between
modeling tasks, and thus also between modeling techniques, are left open because
examination of earlier studies has revealed that different starting points and
sequences are possible. From a modeling technique point of view this means that
“conceptual models” of the system under development can be made
before root definitions or vice versa. An obvious reason why other parts of the
SSM modeling techniques are not evaluated is the universal nature of the method:
different human activity systems require different types of conceptual models
— which can also be seen from the case studies documented — and
therefore their validation in a universal manner is difficult (cf. Section
5.2.4).
The importance of Checkland’s view of method
development (1981, 1991) is that it highlights the continuous learning cycle and
shows that this cycle occurs at several levels: the IS level, the method level
and the ME level. Although Checkland (1981) did not promote the learning cycle
as a mechanism to develop methods (in the same sense as defined in this thesis)
other researchers have applied it directly to ME (Wood-Harper 1985, Avison and
Wood-Harper 1990, Mathiassen et al. 1996, Kaasbol and Smordal 1996). These
studies are described in the following.
The developers of Multiview (Wood-Harper et al. 1985) have
applied an action research cycle when using and testing the method. Similar to
SSM, Multiview was developed as a fixed method and thus it supports narrow
situational adaptability (Harmsen 1997) through in-built flexibility. One major
distinction of Multiview from other methods and from situational adaptability is
that it follows a contingency approach to select among the several techniques it
includes. However, concrete suggestions are not given either for ME criteria, or
for choosing the components of Multiview (Harmsen 1997).
Mathiassen et al. (1996) have applied the action research
cycle for developing a method, called OOA&D (Mathiassen et al. 1995). Here
the applicability of the method is evaluated based on how it has supported
teaching as a learning device. By eliciting experiences from the students in a
class-room setting they have shortened the method refinement cycle. As with
other studies, no concrete ME principles for collecting, analyzing and refining
methods are given. The authors have, however, distinguished some types of method
knowledge which should be specified in ME, namely concepts, guidelines,
principles and patterns, but no further details are given about these. The first
three are covered by our taxonomy: conceptual structure, process and design
objectives. The last one, patterns, deals more with instance level information
as it shows partial solutions to IS modeling tasks in specific domains.
These approaches have, however, several limitations in
addition to their universal view of methods. First and foremost, they do not
include any explicit mechanism to collect, analyze and refine methods. This
would be required for more systematic ME. Thus, after method use, no mechanisms
are used to study whether the method has been applicable. As such they are
general frameworks of method evaluation, rather than applicable principles for
evaluating and refining modeling languages.
Second, in all of them an iterative cycle is carried out
by the method developers rather than by others. For example, in Mathiassen et
al. (1996) the role of students in refining the method is not explained, nor is
the frequency of modifications. As a result, the modifications are highly
dependent on the method developer’s opinions. No indications are given as
to how a larger group of stakeholders can participate in the cycle. In other
words, the process and roles involved in ME are not described.
Third, based on what is reported, the learning cycle is
applied at a general level rather than related to the method knowledge (an
exception is the evaluation of the CATWOE concepts in SSM). Because method
knowledge is defined loosely in these approaches, the approaches do not apply
any ME languages or tools. If such a more systematic approach to method
development had been applied (as proposed by Parsons et al. 1997), it is obvious
that method knowledge could also have been specified and evaluated in more
detail. One reason why such approaches have not been followed may lie in the aim
of situation independent applicability: it is difficult to specify method
knowledge in detail and at the same time for general purposes. A good indication
of this can been seen in the development of the UML method and its versions
(e.g. Booch and Rumbaugh 1995, Booch et al. 1996, 1997) which have become less
specified in terms of details documented in metamodels as the need to satisfy
more general situations has increased.
To summarize, there is a surprising and disappointing lack
of well-documented method evaluation cases, evaluation mechanisms, and criteria.
As a result, it is hard to find out from the ME point of view why methods like
OOD&A (Mathiassen et al. 1996), or Multiview (Avison et al. 1990) are
constructed as they are. For example, which evidence from the use experiences
show that a concept of a cardinality should be used in object models (Mathiassen
et al. 1996) or in entity models (Avison et al.
1990)?
5.2.4 Problems of a posteriori evaluation
The analysis of the evaluation approaches, and especially
their limitations, is not intended to be a criticism of the method development
approaches. Rather it indicates the difficulty of method evaluation and why one
of the key research questions, “Are methods useful?”, has remained
unanswered. In this section our aim is to discuss the difficulties in making
a posteriori, use based, evaluations of methods. This view is important,
since it allows us to describe how incremental ME principles could solve these
problems, and which problems it can not solve.
First, one major reason why method developers have not
evaluated or validated their approaches lies in the difficulty of such a task.
By applying ‘scientific’ research methods to method evaluation and
validation we can not satisfy requirements of scientific theory testing, which
involves reducing domain complexity, controlling data collection, and meeting
replication requirements (see Galliers 1985, Fitzgerald 1991, Grant et al.
1992). The application of a scientific method typically involves construction of
an experiment so that only one or a few factors are identified and studied at a
time. This involves breaking the research subject into smaller parts for
examination with a smaller number of factors. Hence, the experiment is first
conducted in a standard way and then a number of times with one factor changed
(ceteris paribus). A larger set of factors can not be considered at a time
because of their possible interactions. Thus, an understanding of the
applicability of a method, i.e. the big picture, would be constructed on the
basis of these small factors. This type of research setting is, however, hard to
achieve in daily ISD practices.
The replication requirement is also difficult to meet in
ME research because ISD and thus method use is considered situational, or even
unique. In this sense, the requirement for replication could be met only in
situations where the ME criteria are the same. Moreover, if differences in a
method’s applicability occurred between similar (in terms of ME criteria)
ISD efforts, there would probably be factors which had not been identified.
These factors could even be considered as candidate criteria for ME.
In terms of ME, the evolution should deal with inspecting
the applicability of method knowledge according to the ME criteria used in the
construction phase. In other words, a posteriori evaluation could focus
on studying how a priori factors were satisfied. Was the method
applicable in the expected circumstances and contingencies? Did the method help
solving the development problems? Did the method satisfy its users’
requirements? Because of the expected complexity of ME criteria it is difficult
to study one or some of these in different cases and expect that other criteria
do not interfere with the results.
Second, coming up with hypotheses that show the
applicability of methods is problematic, because the hypotheses can not be
formally tested. According to the scientific approach, when several independent
studies have consistently supported the hypothesis it will become a theory or
even a law. This type of proof of method applicability is not available, and as
Fitzgerald (1991, p 662) sarcastically notes, this has troubled IS research very
little. In the context of ME, confirming a hypothesis means that there is some
evidence that a method has been applicable. For example, in the case of
validating the root definition method, Checkland (1981, p 227) notices that the
existence of CATWOE concepts does not guarantee a good definition, but it
provides evidence that in a well-formed definition such concepts are used.
Coming up with hypotheses is, however, important because we can reject them by
finding aspects of applicability which were not fully supported (Kitchenham et
al. 1995). In other words, incremental method refinements occur only when a
method has not been fully applicable.
A third difficulty in studying method applicability is to
ensure that the method has actually been used (Jarke et al. 1994). In terms of
our ME scenarios this means that each source of experience should be based on
verifiable experiences. In our subset of method knowledge, this problem is
bounded: the study of method use in terms of modeling techniques is easier to
analyze than the use of other types of method knowledge, such as process (as in
Jarke et al. 1994), or that design objectives and assumptions of the method are
actually followed. This is also an obvious reason why most validation approaches
focus on conceptual structures and modeling techniques. This does not mean that
the study of method use in terms of modeling techniques is without problems. For
example, method users can apply other modeling techniques than those proposed by
the method engineers, and the study of intermediate models, design sketches, or
different working versions of models is labor-intensive and costly to analyze
for the purposes of ME (Hofstede and Verhoef 1996).
Fourth, the acquisition of experiences is difficult
because experiences are personal and subjective (Nonaka 1994), they deal with
situations that occurred at one point in time (Schön 1983), and they are
often tacit: not all experiences can be made explicit and thus used for method
refinements. Not all method knowledge is explicit: practitioners’ method
knowledge is partly embedded in their practices and can not be fully described.
Furthermore, collecting experiences can be time-consuming and costly. As a
result, method evaluations and refinements seem to be highly subjective. For
example, Fitzgerald (1991, p 668) believes “that the best that can be
achieved is that people may be convinced about a technique’s applicability
and usefulness only by argument and example, not by any concept of scientific
proof”. It must be noted, however, that subjective perceptions and
opinions are vital for the acceptance of methods.
Finally, it is difficult to find what has been the role of
a modeling technique (Checkland 1981). A modeling language can be evaluated
based on what it has abstracted from the current situation (Fitzgerald 1991) but
whether it has provided alternative solutions or choices among them is more
difficult to evaluate. As the analysis of the method evaluation literature
showed, evaluation has mostly been based on the researcher’s concern that
the problem has been “solved” or the problem situation has been
improved (Checkland 1981). On the level of a whole method, an evaluation can be
carried out more easily (e.g. Kitchenham et al. 1995) because method knowledge
can treated in its entirety. Thus, detailed alternative compositions of method
knowledge can be neglected. For example, problem solving capabilities can be
measured based on the number of errors in the developed program, or whether the
IS developed satisfies the user’s requirements. Hence, a method is treated
as a whole. In addition, there remains a question whether the problem has been
really solved with the method, or have they been solved through other means
(e.g. the whole problem disappeared because of external changes). Naturally
method users can judge the influence of methods, but evaluation research does
not discuss enough how the method users’ experiences are collected and
analyzed for improving
methods.
5.2.5 Summary and discussion of method evaluation approaches
In this section we have analyzed approaches for carrying out
a posteriori evaluation of modeling languages. Our aim was to seek
mechanisms for collecting and analyzing methodical experiences, because we
believe that the applicability of a method can only be known when the method is
used. In short, the analysis shows a lack of instruments for evaluation, and
problems in carrying out such evaluations. There seems to be no generally
recognized way to determine if a modeling technique has been applicable. The
reasons are summarized below.
First, the most important limitation of the approaches is
that they do not aim to apply evaluation results to improve the methods. Methods
are considered as a whole and evaluation is not targeted to inspect them in more
detail. Instead of making small changes to the methods, evaluators often seek to
obtain a general proof or disproof. Second, none of the approaches describe the
method evaluation process in detail and only Joosten and Schipper (1996)
describe some explicit instruments for evaluation. Even in their case, the use
of the instruments during the actual evaluation is not explained in detail
(Schipper and Joosten 1996). Some of the instruments, like method metrics, do
not deal with method use at all. Similarly, most of the instruments applied are
used in snap-shot cases. Third, all approaches target the validation to
situation-independent methods. Although they recognize various situations of
method use, they do not recognize that a method could be situation-dependent. In
terms of ME, the evaluation is not targeted only to study whether a method has
been applicable in the current case. Some possible reasons for this focus are
the search for generality, an aspiration to follow scientific methods, and the
method developers’ desire to prove their own methods.
To characterize the incremental approach in relation to
the others described above, we have to focus on detailed method knowledge.
Similarly, our primary aim is not to seek for a universal validation of methods
following a “scientific” proof. Instead we focus on situational
validation in which better applicability is sought by making gradual changes to
a currently used method.
[24] It may be the case that
some validation efforts have been carried out but not described. Similarly, it
is most likely that evaluations are performed during method development, but it
must be noted that method developers have not described how this has been
carried out: i.e. how data is collected, how it is analyzed, and how it has led
to improvements in the method.
[25] For the same reason
SSM has not been included among the methods modeled in Section 4.