4.3 Metamodels for method knowledge
In this section we shall analyze what kind of knowledge ISD
methods include and how this knowledge can be represented. This provides a basis
for identifying essential metamodeling constructs. Method modeling is
illustrated by representing metamodels of three methods, namely Business Systems
Planning (IBM 1984), Structured Analysis and Design (Yourdon 1989a) and Unified
Modeling Language (Booch and Rumbaugh 1995, Booch et al. 1996, 1997). These
methods were selected as examples because of their different nature and area of
use, and because they demonstrate various kinds of knowledge incorporated into
methods. Metamodels of other methods are available through the CASE tools
adapted (cf. appendix), and can be found in Tolvanen and Rossi (1996).
In the following, method knowledge is inspected on two
levels. First, on the metalevel, we apply the ten phases of metamodeling by
specifying individual techniques and by showing how techniques of a method are
interconnected. Second, we briefly demonstrate tool support by showing instance
level models as they are represented in a modeling
tool.
4.3.1 Business Systems Planning
The modeled BSP was based on IBM’s Guide on Information
Systems Planning (IBM 1984).
4.3.1.1 Metamodel of BSP
In the following the metamodel is discussed based on the
metamodeling steps and the use of the GOPRR metamodeling language.
1) Identification of techniques. BSP includes six
techniques: five matrix-based techniques that focus on relationships between
business processes, data classes, systems, and organizational structures of a
company, and a problem sheet to analyze the business problems faced during the
development of IS architectures. Although the method also includes other project
management oriented techniques such as GANTT diagrams, study work plans, and
product lifecycle models, we focus here on design-related techniques. The
techniques of the BSP are defined as graph types with the GOPRR language, and
can be defined as follows (cf. appendix):
|
| Graph
types = {Process/Organization Matrix, Process/System Matrix, Process/Entity
Matrix, System/Entity Matrix, System/Organization Matrix, Problem
Table} |
|
2)
Identification of object types. In BSP, we distinguish five object types,
namely: ‘business process’, ‘data class’ (or entity),
‘organizational unit’, ‘system’, and
‘problem’
[18]. A business process
is defined as “a group of logically related decisions and activities
required to manage resources of the business”. A data class denotes
“a logical grouping of data related to things that are relevant to the
organization” (IBM 1984, p 29). An organizational unit denotes departments
involved in the study, and a system either existing or planned information
system. The object types can be defined as a set:
|
| Object
types = {Business process, Organization, Entity, System,
Problem} |
|
3)
Determination of properties for each object type. Each object type is
described with its naming property, that conveys the meaning of an instance.
Because the name identifies all instances of an object type it is supposed to be
unique in order to avoid homonyms. As a result, it is not possible to have for
example entities or systems with the same name (i.e. values). The
‘problem’ is further characterized with six properties: a
‘problem cause’ to specify the reason for the problem, a
‘problem result’ to specify what is the outcome of the problem, e.g.
how an organization must currently perform because of the problem, a
‘value’ to relate estimated costs to the problem, a ‘causing
process’ to attach a business process that is related to the problem, a
‘causing entity’ to attach an entity related to the problem, and a
‘suggested solution’ to describe a proposed strategy for solving the
problem.
4) Identification of relationships. Each of the
matrix-based techniques focuses on specifying some relationships between two
different object type instances. Accordingly, a relationship called ‘data
usage’ defines the information needs of processes. A ‘system
support’ relationship defines the systems that each process uses, and it
is also applied in another technique to define units of an organization that use
systems. Thus, this relationship type describes similar kinds of connections of
systems in two different techniques, reducing the number of concepts in the
metamodel. A ‘responsibility’ is used to relate stakeholders to
processes: which units of an organization are involved with the process.
Finally, a ‘usage’ relationship specifies the entities managed by
the systems.
|
| Relationship
types = {Responsibility, System support, Data usage,
Usage} |
|
5)
Determination of roles. In BSP all relationships are binary relationships
with two different object types. In GOPRR these relationships are defined
together with the role types and their cardinality rules. The role types
identified are ‘uses’ and ‘used’ for the ‘data
usage’ relationship; ‘uses’ and ‘supports’ for the
‘system support’ relationship; ‘performs’ and ‘is
part of’ for the ‘responsibility’ relationship; and
‘system part’ and ‘data part’ for the ‘usage
relationship’. Although each object type could have their own role types,
and thus we could minimize the number of role types in the metamodel, we choose
separate role types for each relationship type. According to the GOPRR data
model, each role has a cardinality when bound to object and relationship types
(cf. Kelly 1995), defining the minimum and maximum number of role type instances
a relationship can have. In BSP all role cardinalities are one to one (1,1): a
relationship must be connected to only one instance of each role type. The role
types can be defined as a set:
|
| Role
types = { Uses, Used, Supports, Performs, Is part of, System part, Data part
} |
|
6)
Allocation of properties to relationship types and role types. In BSP all
information related to connections between object types is related to
relationship types. The ‘data usage’ relationship type has a
property type called ‘type of use’ since data use can be based on
creation in which a process creates an instance of an entity, or on using the
information contents of an existing entity (more specific usage types, such as
update or read, can also be used).
A ‘responsibility’ relationship type specifies
responsible organizational units for each process. This involvement can be as a
major responsible decision maker in a process, having a major involvement in a
process, or having some involvement in a process. The ‘support’
relationship type has a property called ‘status’ describing whether
the system support for the organizational unit or process is current, planned,
or hybrid (i.e. current and planned). Finally, the ‘usage’
relationship type does not carry additional properties. The allocations of
property types to other types can be defined as follows:
|
| Properties
= { Name, Organization name, Entity name, System name, Relationship name, Type,
Owner, Costs, Value adding, Value, Problem result, Suggested solution, Problem
cause, Causing process, Causing entity, Responsibility type, Support status,
Data
usage} |
|
|
| Properties
of types = {<Organization, Organization name, Owner}>, <Business
process, {Name, Type, Value adding, Costs}>,<System, {System name}>,
<Entity, {Entity name}>, <Problem, {Problem cause, Problem
result, Value, Causing process, Causing entity, Suggested solution}>,
<Responsibility, {Responsibility type}>, <System support,
{Support status}>, <Data usage, {Data usage}>, <Usage,
{Relationship name}>} |
|
7)
Determination of metamodels for individual techniques builds up the
individual techniques by defining the bindings (Kelly 1995, Kelly 1997) from the
relationship types as follows:
|
| Process/Entity
Matrix = {<Data usage, {<Used, {Entity}>, <Uses, {Business
process}>}>} Process/Organization Matrix =
{<Responsibility,{<Performs, Organization}>, <Is part of, {Business
process}>}>} Process/System Matrix = {<System support, {<Uses,
{Business process}>, <Supports, {System}>}>} System/Entity Matrix =
{<Usage, {<Data part, {Entity}>, <System part, {System}>}>}
System/Organization Matrix = {<System support, {<Uses, {Organization}>,
<Supports, {System}>}>} |
8)
Determination of linkages between separate techniques. Since the data
gathered with BSP is interrelated, each object type except a
‘problem’ is a part of several other techniques. Because the
instances of object types are the same in the matrices, i.e. an instance of the
‘organization’ object type can exist in two modeling techniques, no
actual linkages are defined in the meta-data model. In fact, the use of the same
instances between the techniques is more dependent on the process in which the
matrices are built, and thus should be represented with a process
model.
9) Determination of the representational part of the
method. BSP presumes a matrix and a table for representing models. Each
object is represented through its name shown on the axis of a matrix. The
relationships are located in the cells and only two relationship types have
symbols according to the value of their properties: the
‘responsibility’ property can be denoted with different types of
cross (i.e. X, X with a dot, and /), a ‘usage’ relationship between
the ‘data class’ and the ‘system’ object types is shown
with an X, and the rest of the relationships show the value of the
relationship’s property.
10)
Analysis and evaluation of the metamodel. The
described metamodel of BSP has some limitations because of the restrictions made
to BSP, and because of the metamodeling language applied. Naturally, BSP could
be modeled differently. To gather information on the distribution of processes
and data classes
[19], a ‘process’
could be further characterized with additional properties, namely
‘security’, ‘auditability’, ‘volume’, and
‘responsiveness’. For distribution analysis each ‘data
class’ could be specified with its ‘use’, ‘audit’,
‘security’, ‘occurrence’ and ‘currency’
properties. These properties could be attached to the ‘process’ and
‘data class’ types in the process/data class matrix, or a separate
matrix (i.e. a new technique) could be created. The definition of data classes
could also be supported by attaching a new property for categorization: a data
class denotes a person, a place, a thing, a concept, or an event. Furthermore,
to allow a description of each business process and data class a
‘description’ property could be attached to the corresponding object
types. It must be noticed that the search for new method alternatives can lead
to modifications of a method or even to the creation of a wholly new
technique.
The metamodeling language also caused limitations to the
specifications of BSP. Only those concepts of the method that could be described
by the GOPRR model (and can be supported by the CASE tool) were
specified
[20]. First, we could not describe
that each instance of an object type in a matrix must participate at least in
one relationship and can participate in many relationships. This rule requires
a constraint type for object type multiplicity in the metamodeling language, as
discussed in more detail in Section 4.4.1.6. Later extensions of GOPRR include,
however, such a multiplicity constraint (Kelly 1997). Second, we did not
describe that a data class can not be created by more than one process although
it could be possible to divide the data usage relationship into two different
types, i.e. ‘create data class’ and ‘use data class’
relationship types, and a ‘create data class’ could have only one
connected process.
Third, the metamodel does not specify the grouping of a
set of processes, and the composition of a set of data classes, processes, and
their connections into a module of an architecture plan. This would require a
constraint for describing a composite of objects and relationships as discussed
in Section 4.4.2.2. The main reason for excluding these rules of the method was
the limited tool support: the tool used did not provide support for representing
these constructs of a model in a matrix form as described by the method.
Fourth, we could not describe mandatory properties, so it
was not possible to define for example that each business process must have a
non-empty name. The specification of mandatory properties would require an
additional construct in the metamodeling language (cf. Section 4.4.1.3).
Finally, we could not describe the heuristic rules of the method. An example of
these rules is the recommended population of 30-60 data classes that could be
found in an average organization and specified within the matrix models (i.e.
modeling of data classes should not be more detailed in system architecture
plans). Similarly, the capturing of multiplicity of types would require an
additional metamodeling constraint as discussed in Section
4.4.1.9.
4.3.1.2 Instance models of BSP
Because the methods modeled were also adapted in a modeling
tool we can demonstrate the tool support by showing instance level models made
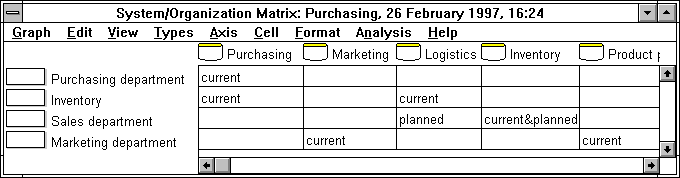
with the metamodel developed. The examples of BSP include two matrixes, namely
process/entity and system/ organization. Both contain instances of all types of
the techniques. In the ‘process/entity’ matrix the horizontal axis
contains entities, and the vertical axis contains processes. The cells of this
matrix include data usage relationships: how each process uses each data class.
In the ‘system/organization’ matrix units of an organization and
systems are shown. The former on the vertical axis and the latter on the
horizontal axis. The cells describe the current status of the system support for
each organization.
FIGURE 4-2 Instance models described with BSP.
These examples show that the metamodel is complete,
because it can represent matrixes as described in the method book, and also
follow the constraints of the method. For example, it is not possible to relate
two business processes directly through a ‘system support’
relationship type. Both of the matrixes show instances of all types found from
these techniques, expect role instances which do not have any explicit
representation in BSP. All in all, the correspondence between the elements of
the metamodel and the instance level is
clear.
4.3.2 Structured Analysis and Design
Although there are several structured methods available (e.g.
DeMarco 1978, Gane and Sarson 1978, Yourdon 1989a) we selected Yourdon’s
(1989a) version with the original ER model (Chen 1976) for closer analysis. It
includes more individual techniques than other dialects with a structured
approach and describes the linkages between different techniques in more
detail.
4.3.2.1 Metamodel of SA/SD
As with BSP, the metamodel of SA/SD is discussed following the
metamodeling steps and documented with the GOPRR metamodeling
language.
1) Identification of techniques. The main
techniques for analysis and design include a data flow diagram (DFD) for
describing a network of functional processes, an entity relationship diagram
(ERD) for specifying the stored data layout of a system, a structure chart (SC)
for describing data interfaces between components, and a state transition
diagram (STD) for specifying the time-dependent behavior of a system. According
to the GOPRR language these techniques can be defined as the following graph
types:
|
| Graph
types = {Data Flow Diagram, Entity Relationship Diagram, Structure Chart, State
Transition
Diagram} |
|
2)
Identification of object types. Unlike BSP, in SA/SD each individual
technique has separate object types. DFDs have three object types,
‘process’, ‘store’ and ‘external’ (sometimes
also called a terminator). ERDs contain three object types,
‘entity’, ‘attribute’ and ‘relationship’,
and both SCs and STDs include only one object type, ‘module’ and
‘state’ respectively.
|
|
| Object
types = {Process, Store, External, Attribute, Entity, Relationship, Module,
State} |
|
3)
Determination of properties for each object type. Because of the
pen-and-paper mentality of SA/SD each object type is described with only a few
properties, shown also in the diagrams: only a naming property type is used for
most of the object types. The name must be unique among all components to avoid
homonyms in the data dictionary. In GOPRR a property type can be renamed with a
local name, hence the same property type (i.e. the ‘name’) can be
labeled with a ‘store name’ and a ‘process name’ but
they still refer to the same property type. Because Yourdon and some other
method developers have proposed the use of numbering for processes a
‘process ID’ is also defined. Other modeling information on object
type instances is typically added into an additional data dictionary including,
for example, a definition and examples of each instance. Therefore, in the
metamodel a ‘documentation’ is added for each object type. The
‘attribute’ object type is furthermore characterized with two
additional property types: ‘type of data’ (e.g. integer, Boolean)
and ‘constraints’ (e.g. primary key, not null).
4) Identification of relationships. Since each
technique includes different object types the relationship types are separate
between techniques as well. In DFDs, SCs and STDs only one relationship type
exists. A ‘data flow’ describes the movement of chunks or packets of
information between the object types of DFDs; a ‘call’ specifies a
synchronous hierarchy of modules in SCs; a ‘transition’ describes
possible changes between states. In ERDs two different types of relationships
exist, one between an ‘entity’ and a ‘relationship’,
called ‘in relationship’, and one between an ‘attribute’
and the other object types called ‘attribute of’. In other words,
both entities and relationships can have attributes.
|
|
| Relationship
types = {Data flow, In relationship, Attribute of, Call, Transition} |
|
5)
Determination of roles. In SA/SD all relationships except the ‘data
flow’ are binary with two instances of role types. According to our GOPRR
definition of roles, a ‘data flow’ has two roles called
‘sends’ and ‘receives’. Since data flows can diverge, a
cardinality constraint for a receiving role is one-to-many (1,M). In GOPRR, a
cardinality constraint defines how many instances of a given role type can exist
for a relationship type instance (Kelly et al. 1996). The other role types
identified are listed in set form below. The ‘sends’ and
‘receives’ roles are also used for the ‘transition’; an
‘owner part’ and an ‘attribute part’ are used for an
‘attribute of’ relationship type; an ‘entity part’ and a
‘relationship role’ is used for the ‘in relationship’;
and a ‘call from’ and a ‘call to’ for the
‘call’ relationship type. The minimum and maximum cardinalities for
the other roles are one-to-one (1,1): an instance of a role type must be
connected to only one instance of a relationship type. The set of role types
is:
|
| Role
types = {Receives, Sends, Entity part, Owner part, Attribute part, Relationship
role, Call from, Call
to} |
|
6)
Allocation of properties to relationship types and role types. In ERD
relationship types do not have any explicit properties: they just relate object
types together. A ‘data flow’ can be characterized with its name and
‘documentation’ property type, a ‘call’ has a
‘call name’ and a ‘parameters’ property type to specify
the parameters sent in the subroutine calls. A ‘transition’
relationship type is characterized with three property types: a
‘condition’ that must be met to change the state, an
‘action’ that the system takes when the state is changed, and
‘documentation’ for adding a textual description of the transition
into the data dictionary.
Role types have properties only in the ERD technique. The
‘entity part’ has a ‘cardinality’ property for
specifying how many times an instance of the ‘entity’ can relate to
another instance of the ‘entity’ through a relationship. The
properties and their allocation to object, relationship, and role types are
specified in GOPRR as follows:
|
| Properties
= {Process name, Process ID, Documentation, Name, Flow name, Cardinality,
Constraints, Type of data, Attribute name, Relationship name, Entity name,
Module name, Parameters, Call name, Action, Store name, Condition, State
name} |
|
| Properties
for types = { <Process, {Process ID, Process name, Documentation}>,
<Store, {Store name, Documentation}>, <External, {Name,
Documentation}>, <Data flow, {Flow name, Documentation}>,
<Attribute, {Attribute name, Type of data, Constraints, Documentation}>,
<Entity, {Entity name, Documentation}>, <Relationship, {Relationship
name, Documentation}>, <Entity part, {Cardinality}>, <Module,
{Module name, Documentation}>, <Call, {Call name, Parameters}>,
<State, {State name, Documentation}>, <Transition, {Condition, Action,
Documentation}>} |
|
7)
Determination of metamodels for individual techniques. Types in each
individual technique are defined by mappings from the relationship types as
follows:
|
| Data
Flow Diagram ={<Data flow,{<Sends, {Process}>, <Receives,{Process,
Store, External}>}>, <Data flow,{<Sends, {Store, External}>,
<Receives,
{Process}>}>} |
|
This
definition follows the rules of DFDs preventing data flows between stores and
externals. Real-time extensions to the DFD could be included by defining the
related types and bindings as follows:
|
| Real-time
Data Flow Diagram = {<Signal flow, {<Event from, {Control}>, <Signal
to, Process, External, Control, Buffer}>}>,<Signal flow, {<Event
from, {Process, External, Buffer}>, <Signal to, {Control}>}>,
<Discrete data flow, {<Sends, {External, Store, Buffer}>, <Receives,
{Process}>}>, <Discrete data flow, {<Sends, {Process}>,
<Receives, {Process, Store, External, Buffer}>}>, <Deactivation
flow, {<Event from, {Control}>, <Deactivated, {Process}>}>,
<Continuous data flow, {<Sends, {Process}>, <Continuous,
{Process}>}>, <Activation flow, {<Event from, {Control}>,
<Activated,
{Process}>}>} |
|
| Entity
Relationship Diagram = {<Attribute of, {<Owner part, {Entity,
Relationship}>, <Attribute part, {Attribute}>}>, <In
relationship, {<Entity part, {Entity}>, <Relationship role,
{Relationship}>}>} |
|
| Structure
Chart = {<Call, {<Call from, {Module}>, <Call to,
{Module}>}>} |
|
| State
Transition Diagram = {<Transition, {<Sends, {State}>, <Receives,
{State}>}>} |
|
8)
Determination of linkages between separate techniques. Unlike in BSP,
techniques of SA/SD model a system using techniques that do not share types,
i.e. use the same type in several techniques. Thus, each technique focuses on
separate types in describing the system. Instance information can, however, be
shared as discussed below. In the following the top-down approach and balancing
rules of SA/SD are modeled with GOPRR using explosion and decomposition based
linkages. First, because the DFD forms the dominant view of the system, each
process can be decomposed into a submodel of a DFD (i.e. functional
decomposition). Processes can also be exploded into a SC to specify subroutines
and modules of a process, and into a STD to specify which transitions change the
state of the controlling process and send or receive data flows from other
processes. Second, as data stores of DFDs and entities of ERDs must be balanced,
each data store in a DFD can be exploded into an ERD to specify the schemas of
the database. Matching store names to entity names on the instance level is
achieved in GOPRR by using the same property type for both types. Only their
local name may differ (i.e. the metamodel definition shows local names for store
and entity, but they refer to the same property type). Third, the STD allows
decomposition to partition states. The same partitioning could be applied for
the SC as well. It is not defined here, because a single SC should not include
modules of several processes. Instead, according to SA/SD the process should be
decomposed into subprocesses that have a simpler structure in terms of a number
of modules and their subroutines.
|
| Data
Flow
Diagram: |
| Explosions
= {<Store, {Entity Relationship Diagram}>, <Process, {Structure Chart,
State Transition
Diagram}>} |
| Decompositions
= {<Process, {Data Flow
Diagram}>} |
| State
Transition
Diagram: |
| Decompositions
= {<State, {State Transition
Diagram}>} |
|
9)
Determination of the representational part of the method. In SA/SD all
techniques are graphical notations except the process specification. During
method implementation all graphical representations were defined as illustrated
in Figure 4-3. Notational aspects that were not possible to define during the
adaptation are the representation of relationships in a functional decomposition
(i.e. relationships mapping to parent diagram and represented as
“dangling” links with one connected object type only), and the tree
structure of the SC diagram (i.e. each calling module should be located above
the modules called). Other techniques do include similar location
recommendations though. For example, in DFD externals are most often placed on
the sides of a diagram.
10)
Analysis and evaluation of the metamodel.
Because of the several informal definitions of SA/SD, it is possible to model
techniques in many ways. For example, a ‘decision’ in the SC could
be included into the metamodel either by specifying a new role type, such as a
‘decision’, by adding a relationship type, such as a ‘call
based on decision’, or by adding a property type for the
‘call’ relationship (see also Welke 1988). Moreover,
supertype/subtype relationships and indicators for associative object type in
ERD are not modeled
[21]. Also, the data
dictionary and process specification are not included, although one can form a
dictionary by using information entered into the documentation properties
attached to types (i.e. using form conversion mechanisms, cf. Section 2.3.2).
A more important aspect of evaluation is how completely
the SA/SD method is modeled and therefore implemented into a CASE tool. Because
of limitations in GOPRR and OPRR, some aspects of SA/SD were not captured and
supported by tools. First, in a data flow diagram a process should be described
in more detail either with an additional subdiagram or with a structure chart,
but not by using both techniques. Such a restriction between explosion and
decomposition can not be specified with GOPRR. These require a more detailed
definition (cf. Section 4.4.2.3). Second, iteration calls between the modules
could not be restricted with GOPRR, requiring an additional metamodeling
constraint (cf. Section 4.4.1.8). Third, transformations that could be
automated, such as transformations from a DFD into a SC at the same level, are
not supported. Fourth, and similarly to the BSP metamodel, identifiers and
uniqueness of property values were not defined adequately. It was not possible
to restrict these to the scope of a single diagram. For example, according to
the metamodel each name of a state is unique among all diagrams, not just inside
one diagram as required. To model these rules a metamodeling language should
allow the specification of different scopes for the method rules (cf. Section
4.4).
Fifth, the metamodel does not support all the balancing
rules of SA/SD, such as a correspondence of data stores to entities (based on
their names) or correspondence of conditions in state transition diagrams to
data flows. Furthermore, dependencies of the property values should be included
into the metamodel as well: the possible values for a condition in a state
transition diagram can be only those defined in data flows that a related
control process receives. Modeling of the balancing rules and dependencies of
related instances would require additional metamodeling constructs as discussed
in Section 4.4.2.4. Finally, the metamodel does not include multiplicity rules
defining the number of roles an object can participate in (cf. Section
4.4.1.5).
4.3.2.2 Instance models of SA/SD
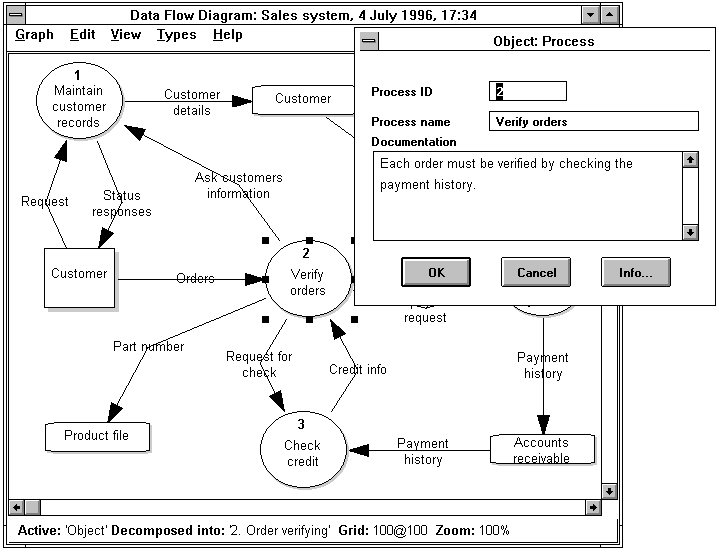
Figure 4-3 illustrates an example of the use of two
techniques in the modeling tool. The upper window shows some processes and data
flows of a sales system. To show instances of property definitions and a
decomposition, a process called verify orders is viewed with its properties, and
the status bar of the window shows that the process is decomposed into a
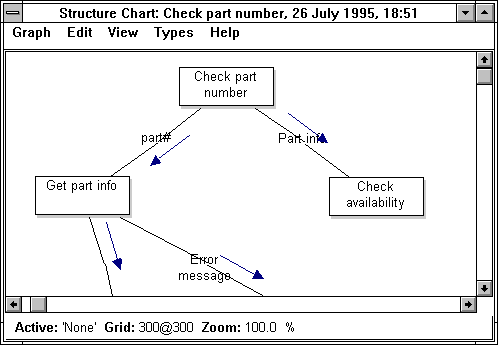
subdiagram. The lower window shows a structure chart.
FIGURE 4-3 Two instance models of SA/SD: a data flow
diagram and a structure
chart.
4.3.3 Unified Modeling Language
After modeling two relatively simple methods we shall next
model one of the most complex methods found, the Unified Modeling Language
(UML). Because the standardization of UML was under development at the time of
metamodeling, the metamodels discussed here are based on several publications
about the method and its versions (cf. Booch and Rumbaugh 1995, Booch et al.
1996, 1997).
4.3.3.1 Metamodel of UML
As with the earlier metamodeling cases, specification of UML
follows the metamodeling process described in Section 4.2.2.
1)
Identification of techniques. UML includes as
its main techniques a class diagram, a collaboration diagram and a use case
diagram. Other diagram types
[22], mentioned
below as graph types, have a simpler structure and they are not applied as
often. We also make some simplifications in techniques by joining the category
diagram and class diagram as they include the same types. The only difference is
that a category diagram shows instances of a ‘category’ only,
whereas class diagrams can include instances of both a ‘class’ and a
‘category’. The composite diagram has been included in the graph
types to support context diagrams for instances of classes (called composites in
UML). In a later extension (Booch et al. 1996, 1997) all techniques are expected
to use categories, renamed now as package, for organizing large
models.
|
| Graph
types = {Class diagram, Use case diagram, Collaboration diagram, State diagram,
Component diagram, Deployment diagram, Operation table, Composite
diagram} |
|
2)
Identification of object types. Because of the unfinished documentation
and relatively complex conceptual structure of UML, several alternative
interpretations and consequent modeling decisions of object types can be made.
First, template classes are not distinguished as a separate type because
template parameters denoting generic classes are not mandatory, i.e. a
‘class’ without defined template parameters is considered to be an
ordinary class. Second, a utility class is not identified as its own object
type. Rather it is distinguished with a property attached to each class
(discussed in the next task).
In addition to the object types of a class diagram, the
GOPRR metamodel includes some constraints of UML modeled as object types, such
as an alternative association (i.e. ‘or-constraint’) and
‘parallel inheritance’. Parallel inheritance hierarchies, however,
could also be described with a property type referring to another hierarchy of
the same superclass (i.e. to another inheritance relationship). The fourth major
modeling alternative would be to distinguish objects of a class diagram and a
collaboration diagram into separate types instead of using a single type in both
techniques. Overall, the following set of object types describes one possible
outcome of object type identification.
|
| Object
types = {Class, Instantiated class, Object, Category, Or-constraint, Parallel
inheritance, Actor, Use case, Operation specification, Note, Node,
Specification, Main program, Body, State, Stop,
Start} |
|
3)
Determination of properties for each object type. Compared to other types
of methods, object-oriented methods in general, and UML in particular, have more
property types. For this reason they are specified here distinct from other
metatypes. In contrast to the methods above, in UML some properties are atomic,
single valued, whereas others consist of a set of other property types. For
example, an attribute of a class has a more detailed internal structure with its
own property types (such as an initial value and a data type of an attribute).
In the following we first define the properties of object types and later the
non-atomic properties.
A class is identified by its name and by the name of a
possible category to which it belongs. Although class names must be unique in
the enclosing category, the same class name can be used as a type of a
parameter. In GOPRR this is modeled by using both global and local names for
property types (see also the metamodel of state diagrams in Section 3.3.3). For
example, a property type ‘class name’ can be renamed with a local
name for describing a data type of a parameter.
An ‘Is utility?’ property type is used to
define global attributes and operations; ‘overridability’ (e.g.
deferred, leaf, extensible, virtual) is used to define how a class may be
overridden by a subclass. ‘Template parameters’ is used for defining
generic classes called templates in UML. An object type ‘instantiated
class’ refers to a template class in two ways: properties of
‘instantiated class name’ refer to a name of a template class, and
‘values’ is a set of template parameter values. An
‘instantiated class’ can not have its own attributes or operations
as these are derived from the template class. Categories are identified by a
‘category name’ and it has an additional ‘documentation’
property type. These are also added to ‘class’ and to
‘instantiated class’.
A ‘class name’ is the same property for
‘object’ and ‘class’ object types, showing that an
object can not belong to other classes than those defined. Hence, objects are
dependent on the existence of classes. Other property types for an
‘object’ are a ‘multiplicity’ type for specifying the
number of instances a related class can have at a time; and ‘values’
which denotes instances of an attribute of a class. Notes are specified by one
property type only, named here ‘description’.
Other object types of UML are identified and described
just by their name and additional ‘documentation’ property type.
Only a ‘node’ object type can have a ‘multiplicity’
property type, and a ‘state’ object type has ‘attribute
values’ and ‘operations’ property types. The name spaces of
identifying properties are distinguished by using separate property types for
identifiers of object types, except in a dependency diagram. Here, the metamodel
uses the same property type ‘name’ for identifying several object
types. By defining the instances of this property type as unique we can specify
that the same value for a property can not be used to identify other instances
of object types in a deployment diagram. Thus, instances of
‘specification’ and ‘body’ can not have the same value
for this property.
|
| Properties
for object types =
{<Class,
{Class name, Is utility?, Category, Stereotype, Overridability, Attributes, Operations, Documentation,
Template
parameters}>,<Category,
{Category name,
Documentation}>,<Instantiated
class, {Instantiated class name, Values, Documentation}>,<Object,
{Object name, Class name, Values,
Multiplicity}>,<Note,
{Description}>,<Use
case, {Use case name, Documentation}>,<Actor, {Actor name,
Documentation}>,<State, {State name, Attribute values, Operations,
Documentation}>,<Operation specification, {Name, Responsibilities,
Inputs, Returns, Modified objects, Preconditions, Postconditions}>,<Specification,
{Name, Documentation}>,<Main program, {Name,
Documentation}>,<Body, {Name, Documentation}>,<Node, {Name,
Stereotype, Multiplicity, Documentation}>} |
|
In
UML, some property types have an internal structure. Each attribute has a basic
format requiring property types for an ‘attribute’, namely an
‘attribute name’, a ‘data type’, an ‘attribute
type’, and an ‘initial value’. Similarly, an
‘operation’ has an ‘operation name’,
‘parameters’ and a ‘return value’. The
‘parameters’ property type is a collection consisting of parameters
each having three property types, namely a ‘parameter name’, a
‘parameter type’ and a ‘default value’. To support
specific programming language constructs some additional property types are
attached for both attributes and operations. These include
‘constraints’ and ‘visibility’ (e.g. public, private,
protected in C++). Moreover, ‘overridability’ (applicable for both
classes and operations) and ‘method body’ are also attached for
operations. Finally, parameters for template classes have a name and a type.
|
| Derived
property types =
{<Attributes,
{<Attribute, {Attribute name, Data type, Attribute type, Initial
value, Constraints,
Visibility}>}>,<Operations,
{<Operation, {Operation name, Parameters, Return value,
Constraints, Visibility, Overridability, Method
body}>}>,<Parameters,
{<Parameter, {Parameter name, Parameter type, Default
value}>}>,<Template
parameters, {<Template parameter, {Parameter name, Parameter
type}>}>} |
|
4)
Identification of relationships. In UML, there is a clear distinction
between methods which apply several relationship types, and those using only one
or two relationship types. More specifically, class diagrams and use case
diagrams apply more relationship types than other techniques. In the following
definition the number of necessary types is reduced by applying a
‘dependency’, a ‘note connection’ and an
‘inheritance’ relationship types in several techniques instead of
having their own variants in each technique.
|
|
| Relationship
types = {Association, Ternary association, Aggregation, Instantiation,
Dependency, Note connection, Inheritance, Connection, Message link, Uses,
Extends, Participation, Transition} |
|
5)
Determination of roles. As in other methods, binary relationships
dominate in UML. Some of the relationships are, however, n-ary at the instance
level and some also at the type level. At the instance level, an
‘inheritance’ and an ‘association’, like their subtypes
‘aggregation’ and ‘ternary association’, necessitate
roles with a maximum cardinality greater than one. For example, a
‘specialization’ role type in an ‘inheritance’
relationship can have more than one instance. Hence the maximum cardinality for
a ‘specialization’ role type is many. At the type level, UML has
optional role types connected to the relationship types which already have two
other role types. Hence the minimum cardinality constraint of GOPRR is defined
here as one for mandatory roles and zero for optional role types. Since all
optional role types (i.e. ‘link attribute’, ‘or’ and
‘parallel’) can occur only once in a related relationship type
instance, the maximum cardinality defined for them is one.
As with relationships the same role types are used in
several techniques, such as ‘specialization’ and ‘note
part’, reducing the size and complexity of the metamodel. The set of role
types is:
|
| Role
types = {Instantiates, Is instantiated, Note part, Object part, Has dependents,
Is dependent, Associates, Qualified association, Link attribute, Specialization,
Generalization, Parallel, Or, Part, Whole, Sends, Receives, Uses, Participates,
Is used, Extends, Is extended, Receive message, Send message,
Connected} |
|
6)
Allocation of properties to relationship types and role types. Compared
to the earlier methods, UML relationship and role types have many properties.
This is also highlighted by adding some additional programming language specific
property types. For example, the ‘inheritance’ relationship type has
property types ‘visibility’ and ‘virtual?’ denoting
inheritance structures in C++. In addition, associations can be defined as
derived, messages have a ‘sequence’ for numbering,
‘arguments’ sent and values returned along the message, an
‘indicator’ for describing exclusive iteration and condition
indicators of a message, and a ‘link type’ for typing message links
(e.g. association, argument, global, variable).
Association role types have several property types. These
include a description of the role names, their visibility (i.e. public, private,
protected), the existence of an explicit order of the set of classes associated
with a single object, how the role outside the class is accessed (i.e. read,
write, both or none), and how many instances of the class can be associated with
one instance in another class with ‘multiplicity’. Multiplicity is
also needed for describing how many components an aggregate class can have, and
how many aggregates a component class can be part of.
In the ‘state diagram’, the
‘transition’ is also specified with several property types: an
‘event’ triggering a state transition, a ‘condition’ to
be met before the state transition can occur, and an ‘action’
resulting in a change in the state of the object. The action is realized by
sending a message to an object or modifying a value of an attribute. Both events
and actions have arguments, which refer to a specific value corresponding to a
parameter. Finally, a role type ‘receive message’ has an additional
‘adornment’ property.
|
| Properties
for relationship and role types =
{<Inheritance,
{Visibility, Virtual?,
Discriminator}>,<Association,
{Association name, Is derived?}>,<Ternary
association, {Association name, Is derived?}>,<Aggregation,
{Name}>,<Associates,
{Role name, Visibility, Access, Multiplicity, Ordered?}>,<Part,
{Multiplicity}>,<Qualified
association, {Role name, Visibility, Access, Multiplicity,
Ordered?, Qualifier}>,<Whole,
{Multiplicity}>,<Message
link, {Sequence, Name, Arguments, Return type, Link type,
Indicator}>,<Receive
message, {Role name, Adornment}>,<Transition,
{Event name, Arguments of event, Condition, Action, Arguments of
action, Documentation}>,<Connection,
{Name}>} |
|
7)
Determination of metamodels for individual techniques. In the following
bindings for each technique are described. In the class diagram, both
associations have four roles, of which a ‘link attribute’ and
‘or’ constraint are optional. Inheritance hierarchies between
categories and classes are distinguished. Thus, inheritance hierarchies between
these object types can not be mixed. Both of these hierarchies have an optional
‘parallel’ role showing to simultaneous specializations. A use case
diagram also allows inheritance among categories, although use cases could also
be considered as classes with their own inheritance hierarchy. Moreover, use
cases can be related with ‘uses’ and ‘extends’
relationships and connected to actors with ‘participation’
relationships.
Other graph types have simpler bindings: a composite
diagram is used for describing the associations and aggregations of objects in
the context of a class, and a collaboration diagram focuses on message sending
between the objects. A state model is similar to that modeled with SA/SD and an
‘operation table’ has no bindings. Finally, the component and
deployment diagrams describe the physical design and apply a dependency
structure among all object types as described below.
|
| Class Diagram =
{Instantiates, {<Instantiates, {Class}>,<Is instantiated,
{Instantiated class, Object}>}>,<Dependency, {<Has
dependents, {Category, Class}>, <Is dependent, {Class, Category,
Object, Instantiated class }>}>,<Note connection, {<Note
part, {Note text}>,<Object part, {Object, Class,
Category}>}>,<Inheritance, {<Specialization,
{Class}>,<Generalization, {Class}>,<Parallel, {Parallel
inheritance}>}>,<Inheritance, {<Specialization,
{Category}>,<Generalization, {Category}>,<Parallel,
{Parallel inheritance}>}>,<Inheritance, {<Specialization,
{Instantiated class}>,<Generalization, {Instantiated
class}>,<Parallel, {Parallel
inheritance}>}>,<Aggregation, {<Whole, {Class}>,<Part,
{Class}>}>,<Association, {<Associates,
{Class}>,<Associates, {Class}>,<Or,
{Or-constraint}>,<Link attribute, {Class}>}>,<Ternary
association, {<Associates, {Class}>,<Associates,
{Class}>,<Or, {Or-constraint}>,<Link attribute,
{Class}>}>}
Use case diagram = {<Dependency,
{<Has dependents, {Category}>,<Is dependent,
{Category}>}>,<Uses, {<Uses, {Use case}>,<Is used,
{Use case}>}>,<Note connection, {<Note part, {Note
text}>,<Object part, {Actor, Use case, Category}>}>,
<Extends, {<Extends, {Use case}>,<Is extended, {Use
case}>}>,<Inheritance, {<Specialization, {Category}>,
<Generalization, {Category}>}>,<Participation,
{<Participates, {Actor}>,<Participates, {Use case}>}>}
Composite diagram = {<Aggregation,
{<Whole, {Object}>,<Part, {Object}>}>,<Association,
{<Associates, {Object}>,<Associates, {Object}>}>}
Collaboration Diagram = {<Message
link, {<Send message, {Object}>,<Receive message,
{Object}>}>,<Note connection, {<Note part, {Note
text}>,<Object part, {Object}>}>}
State Diagram = {<Transition,
{<Sends, {Start, State}>,<Receives, {Stop,
State}>}>,<Note connection, {<Note part, {Note
text}>,<Object part, {State}>}>}
Component Diagram = {<Dependency,
{<Has dependents, {Category, Specification, Main program,
Body}>,<Is dependent, {Category, Specification, Main program,
Body}>}>,<Note connection, {<Note part, {Note
text}>,<Object part, {Category, Specification, Main program,
Body}>}>} Deployment Diagram = {<Connection, {<Connected,
{Node}>,<Connected, {Node}>}>,<Dependency, {<Has
dependents, {Node}>,<Has dependents, {Node}>}>,<Note
connection, {<Note part, {Note text}>,<Object part, {Node,
Category}>}>,<Dependency, {<Has dependents,
{Category}>,<Is dependent, {Category}>}>} |
|
8)
Determination of linkages between techniques. Because UML suggests
several modeling techniques, linkages between them are vital to integrate
models. The following explosion and decomposition operators were specified:
categories can be attached to class diagrams which can also contain other
categories. A class can also be exploded to a collaboration diagram showing the
interaction between its objects, to an operation table for describing a
functional model (also applicable for actors, use cases, states and for objects
of a collaboration diagram), and to a state model for describing the temporal
evolution of an object of a given class. A class can also be decomposed into a
composite diagram to describe a specific context for its instances. Similarly
classes, actors and use cases can have related state models through an explosion
link. State models can be nested through decompositions of states into
substates. Finally, a decomposition of categories into instances of the same
graph type is added to class, use case, component and deployment
diagrams.
|
| Class
Diagram: |
| Explosions
= {<Class,
{Collaboration diagram, Operation table, State
diagram}>} |
| Decompositions
= {<Class, {Composite
diagram}>,<Category,
{Class
diagram}>} |
|
|
| Use
Case
diagram: |
| Explosions
= {<Actor, {Operation table, State diagram}>,<Use case, {Operation
table, State diagram}>} |
| Decompositions
= {<Category, {Use Case
diagram}>} |
|
|
| Collaboration
Diagram: |
| Explosions
= {<Object, {Operation
table}>} |
| Decompositions
=
{} |
|
| State
Diagram: |
| Explosions
= {<State, {Operation
table}>} |
| Decompositions
= {<State, {State
diagram}>} |
|
| Component
Diagram: |
| Explosions
=
{} |
| Decompositions
= {<Category, {Component
diagram}>} |
|
| Deployment
Diagram: |
| Explosions
=
{} |
| Decompositions
= {<Category, {Deployment
diagram}>} |
|
9)
Determination of the representational part of the method. On the
notational side, the following aspects could not be represented. First, nested
forms could not be specified in the same diagram with categories, composites and
state diagrams. As the definitions show this was partly solved by using
explosion and decomposition structures, even though the relationships between
the components of two or more categories can not then be represented. Second,
concurrent substates could not be represented by partitioning the state symbol.
Third, different symbols for classes could not be defined based on the values of
their properties, such as an additional box above the class symbol if parameters
are defined (i.e. a symbol for the parameterized class).
10) Analysis and evaluation of the metamodel. In
addition to the representation dependent aspects, the metamodel of UML could
have been made differently. Some aspects of the textual method description were
not included, since they were not supported by the parallel metamodel definition
given by Booch and Rumbaugh (1995). Metamodels could also include additional
programming language specific constructs. In fact, Booch and Rumbaugh, even
though seeking for a standard notation for object-oriented methods, recommend
situation-bound modifications to align concepts closer to a specific programming
language (e.g. Booch and Rumbaugh 1995, p. 4).
A more important aspect of evaluation is how completely
UML could be adapted in a CASE tool. This aspect is discussed in the following.
The modeling of UML emphasizes the need of scopes for identity and uniqueness of
properties. An identifier consisting of two property type instances could not be
modeled, nor could the dependency between partial identifiers: the same category
should not have more than one class with the same name, and the same class
should not have more than one instantiated object with the same name. Modeling
of these would require additional constructs in the metamodeling
language.
The design orientation of UML and its close relationship
to programming languages necessitates support for the naming policy of
attributes and operations, such as the naming of classes in Smalltalk with a
capitalized first letter (Hopkins and Horan 1995). Some of these syntax
definitions would require dynamic changes in other property types. For example,
if a parameter is not defined a colon should be omitted from the operation
specification. These would require a specific syntax for property values and for
checking of property type values (cf. Section 4.4.1.4). The GOPRR model could
not describe the multiplicity rules which were applied in the OPRR metamodel.
For example, the UML metamodel does not include restrictions on multiple
inheritance (i.e. a class can participate several times in a specialization
role) or that a class can be part of multiple classes through the aggregation
relationship. To model multiplicity rules of methods an additional metamodeling
construct would be needed (cf. Section 4.4.1.6).
Because of the wide variety of different graph types, the
modeling of UML also highlights requirements to model interconnected methods and
complex objects. In interconnections, the metamodel does not allow an operation
to be exploded into an operation table. Instead this is carried out by exploding
the whole class. Nor can we represent that each state diagram needs to be
connected to a class diagram (through an explosion), or to a higher-level state
(through decomposition). Modeling of these would necessitate a more detailed
specification of interconnections (as discussed in Section 4.4.2.3). In a
similar vein, complex objects could not be specified adequately with a
decomposition, or an explosion. An example of such a situation is when a
component in a complex object (e.g. a substate) can belong to many aggregate
objects (e.g. to composite states). Among states, the substates can belong only
to one composite state, whereas an object can belong to more than one composite
class (Booch and Rumbaugh 1995, p 11, 33). Modeling these complex objects
completely would require additional constructs in metamodeling languages (as
discussed in Section 4.4.2.2). Finally, modeling UML requires a specification of
related properties; i.e. two or more property instances have the same value. An
example of this is the requirement specifying that a state model should not have
an action that is not defined as an operation in the related class, or that a
state should not have attribute values that are not equivalent to those defined
in a related class. Similarly, an operation in a class diagram and a message in
a collaboration diagram can have several common values, such as name and
arguments, which refer to the same property instances. To model this sharing of
the same values among different types would require additional constructs in the
metamodeling language(cf. Section
4.4.2.4).
4.3.3.2 Example models
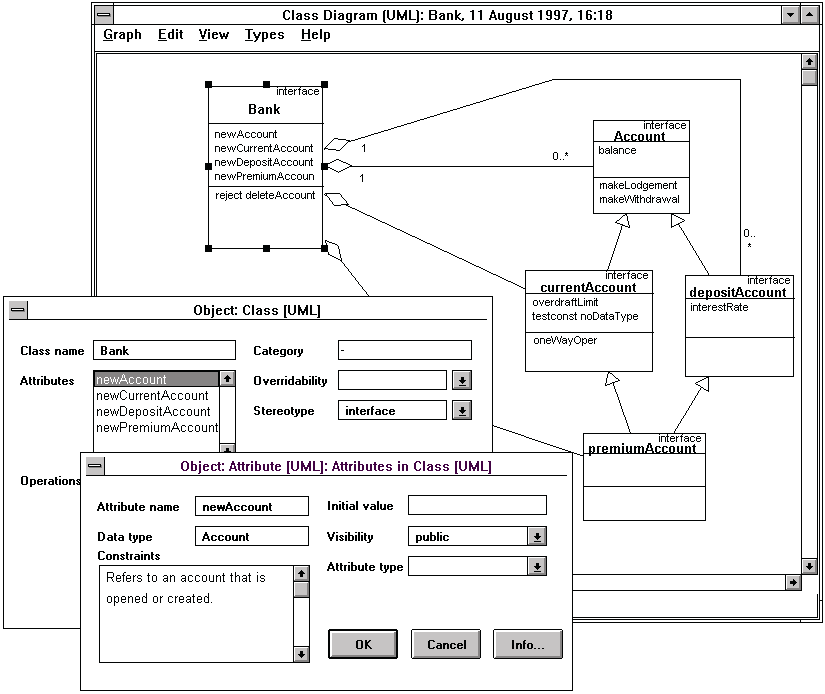
Part of the tool adaptation for UML is shown in Figure 4-4.
The figure illustrates a class diagram for a banking application in which all
classes belong to a stereotype interface that enables code generation for Corba
IDL (Iona 1997). The cardinalities of the aggregation relationship are shown
between classes named a bank and an account: a bank has multiple accounts, but
each account must belong to only one bank. Inheritance relationships based on
single and multiple inheritance are shown as lines with an arrowhead. Multiple
inheritance is illustrated as the class named premium account inherits both
current account and deposit account.
Since UML includes more complex data types than earlier
methods, we show dialogs below the class diagram to illustrate the properties of
a class and an attribute. The property dialog of an attribute newAccount refines
the instance selected from the attribute list of the bank class.
FIGURE 4-4 An example class diagram of
UML.
4.3.4 Summary
Metamodeling, if properly performed, leads to a detailed
understanding of the phenomena under examination. In this section we inspected
the conceptual structure of methods in computer-aided modeling tools. Of all 17
methods modeled, three were taken into a closer examination. The structures of
the methods were identified, classified and represented with meta-data models.
Moreover, CASE tool support was created using the metamodel to validate the
method specifications. These efforts form the background for our study of
requirements for method modeling languages in the next section.
[18] Hereafter we use
apostrophes in the text to denote the types of a method.
[19] The analysis of
distributed information systems is an extension of a basic BSP and thus excluded
from our method analysis. For the same reason, an optional technique for
analysis of critical success factors was also excluded. Similarly, techniques
for ranking development priorities and project management were not
included.
[20] It must be noted
that not all method knowledge described with the GOPRR model is included into
the set-based definitions. These include cardinality constraints of roles, data
types of properties, identifiers of types, and uniqueness of property types.
These are, however, implemented in the tool-based metamodels and contained into
the discussion of the essential constructs of metamodeling languages in Section
4.4.
[21] Modeling of these
concepts, however, is taken into account and specified in the metamodel of UML
(cf. Section 4.3.3).
[22] We also excluded
the event trace diagram since it is based on the same underlying semantics as
the collaboration diagram (Booch and Rumbaugh 1995).