Luku 3 Posteriorin simulointi Markovin ketju Monte Carlo -menetelmällä
3.1 Markovin ketju Monte Carlo lyhyesti
Markovin ketju Monte Carlossa (Markov chain Monte Carlo, MCMC) havaintoja posteriorijakaumasta simuloidaan Markovin ketjusta, jonka tasapainojakauma on kiinnostuksen kohteena oleva posteriorijakauma.
3.2 Markovin ketju
Määritelmä 3.1 (Markovin ketju) Satunnaismuuttujien jonoa \(\theta^{(0)},\theta^{(1)},\theta^{(2)},\ldots\,\) kutsutaan Markovin ketjuksi mikäli kaikilla \(t > 0\) \[ p(\theta^{(t+1)} | \theta^{(0)},\ldots,\theta^{(t)}) = p(\theta^{(t+1)} | \theta^{(t)}). \]
Satunnaismuuttujien \(\theta^{(0)},\theta^{(1)},\theta^{(2)},\ldots\) mahdollisia arvoja kutsutaan usein tiloiksi ja näiden muodostamaa joukkoa tila-avaruudeksi. Markovin ketjussa tilasiirtymien todennäköisyydet (tai tiheydet, jos tila-avaruus on jatkuva) riippuvat ainoastaan nykyisestä tilasta. Sillä, kuinka nykyiseen tilaan on päädytty, ei ole merkitystä tuleviin tilasiirtymiin. Tiettyjen ehtojen vallitessa voidaan osoittaa, että kun \(t \rightarrow \infty\), satunnaismuuttujan \(\theta^{(t+1)}\) jakauma suppenee kohti tasapainojakaumaa, joka ei riipu ketjun alkuarvosta \(\theta^{(0)}\).
Tehtävänä on siis luoda Markovin ketju, jonka tasapainojakauma on haluttu posteriorijakauma. Tämän toteuttamiseen on olemassa useita algoritmeja, joista tärkeimpiä käsitellään jatkossa. Lisäksi tulee valita Markovin ketjun alkuarvo ja selvittää milloin ketju on supennut tasapainojakaumaansa.
3.3 Globaali ja lokaali tasapainoehto
Tarkastellaan Markovin ketjua, jonka tila-avaruus \(S\) on diskreetti. Tällöin siirtymää tilasta \(i\) tilaan \(j\) voidaan merkitä todennäköisyydellä \(p_{ij}\).
Määritelmä 3.2 (Tasapainojakauma) Markovin ketjun tasapainojakauma on jakauma \(\{\pi_i, i \in S\}\), joka toteuttaa globaalin tasapainoehdon \[ \sum_{i \in S} \pi_i p_{ij} = \pi_j \textrm{ kaikille } j\in S. \]
Globaalissa tasapainoehdossa tarkastellaan siis erilaisia tapoja saapua tilaan \(j\). Kun kunkin lähtötilan \(i\) todennäköisyys määrätään tasapainojakaumasta, päädytään tilaan \(j\) tasapainojakauman mukaisella todennäköisyydellä \(\pi_j\).
Tasapainojakauman olemassaolo voidaan osoittaa, mikäli tietyt ketjua koskevat ehdot täyttyvät. Näistä ehdoista tärkein on pelkistymättömyys (irreducibility), joka takaa sen, että siirtyminen mistä tahansa tilasta \(i\) mihin tahansa tilaan \(j\) on mahdollista äärellisellä määrällä siirtymiä.
Globaalin tasapainoehto ei ole kovinkaan käyttökelpoinen, kun tavoitteena on konstruoida Markovin ketju, jolla on annettu tasapainojakauma. Simulointialgoritmit perustuvatkin vahvempaan lokaaliin tasapainoehtoon \[ \pi_i p_{ij} = \pi_j p_{ji} \textrm{ kaikilla } i,j \in S. \] Lokaalissa tasapainoehdossa tarkastellaan siis siirtymää kahden tilan välillä. Ehdon mukaan tasapainotilanteessa on yhtä todennäköistä havaita siirtymä tilasta \(i\) tilaan \(j\) kuin tilasta \(j\) tilaan \(i\). Lokaalista tasapainosta seuraa globaali tasapaino seuraavalla tavalla \[ \begin{aligned} \sum_{i \in S} \pi_i p_{ij} = \sum_{i \in S} \pi_j p_{ji} = \pi_j \sum_{i \in S} p_{ji} = \pi_j. \end{aligned} \]
3.4 Gibbsin algoritmi
Gibbsin algoritmissa Markovin ketju rakennetaan siten, että mallin parametreja päivitetään yksi kerrallaan. Uusi arvo generoidaan ehdollisesta jakaumasta, jossa ehtoina ovat muut parametrit. Aluksi mallin parametrit jaetaan \(k\) komponenttiin \(\theta=(\theta_1,\theta_2,\ldots,\theta_k)\). Yleensä komponentit ovat skalaariparametreja, mutta ne voivat olla myös vektoreita. Gibbsin algoritmin vaiheet ovat:
Aseta alkuarvot \(\theta_1^{(0)},\theta_2^{(0)},\ldots,\theta_k^{(0)}\) ja aseta \(t=0\)
Generoi ensin \(\theta_1^{(t+1)}\) jakaumasta \(p(\theta_1 | \theta_2^{(t)},\ldots,\theta_k^{(t)})\) ja sitten \(\theta_2^{(t+1)}\) jakaumasta \(p(\theta_2 | \theta_1^{(t+1)},\theta_3^{(t)},\ldots,\theta_k^{(t)})\) (jossa \(\theta_1\) on jo siis päivitetty). Jatka näin kunnes kaikki komponentit on päivitetty ja kasvata sitten iteraatiota \(t\) yhdellä.
Toista vaihetta 2 riittävän monta kertaa (yleensä tarvitaan tuhansia iteraatioita).
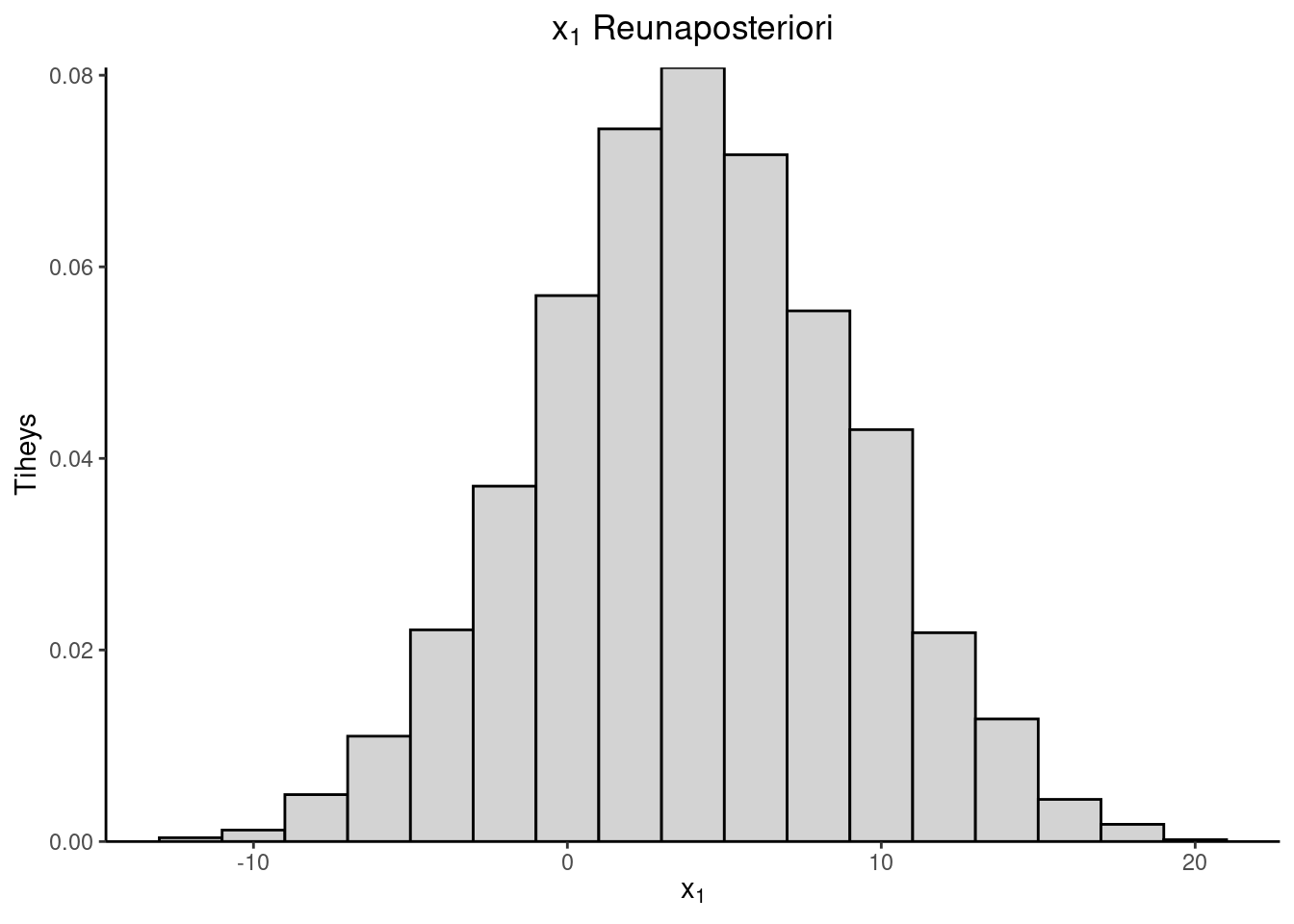
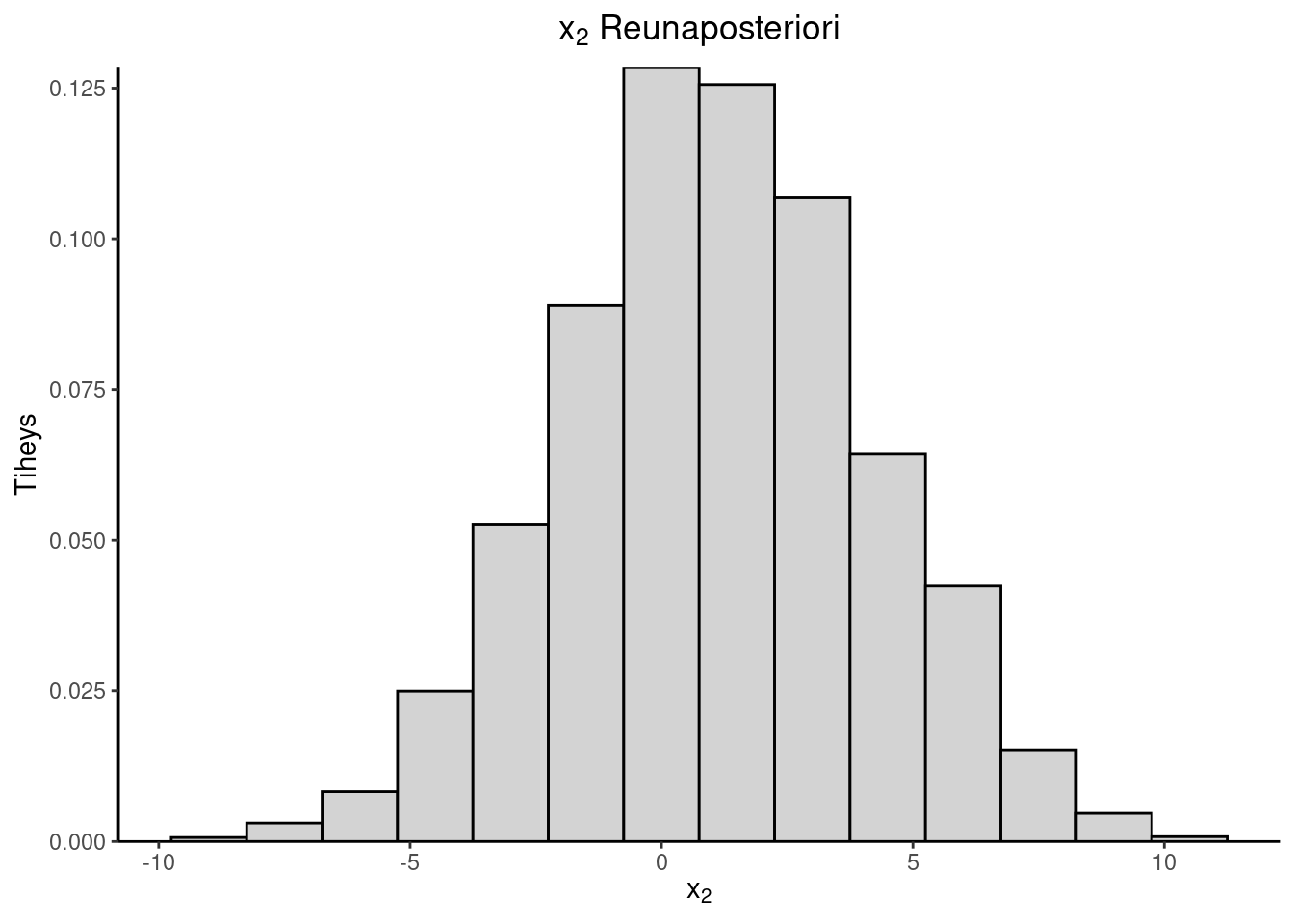
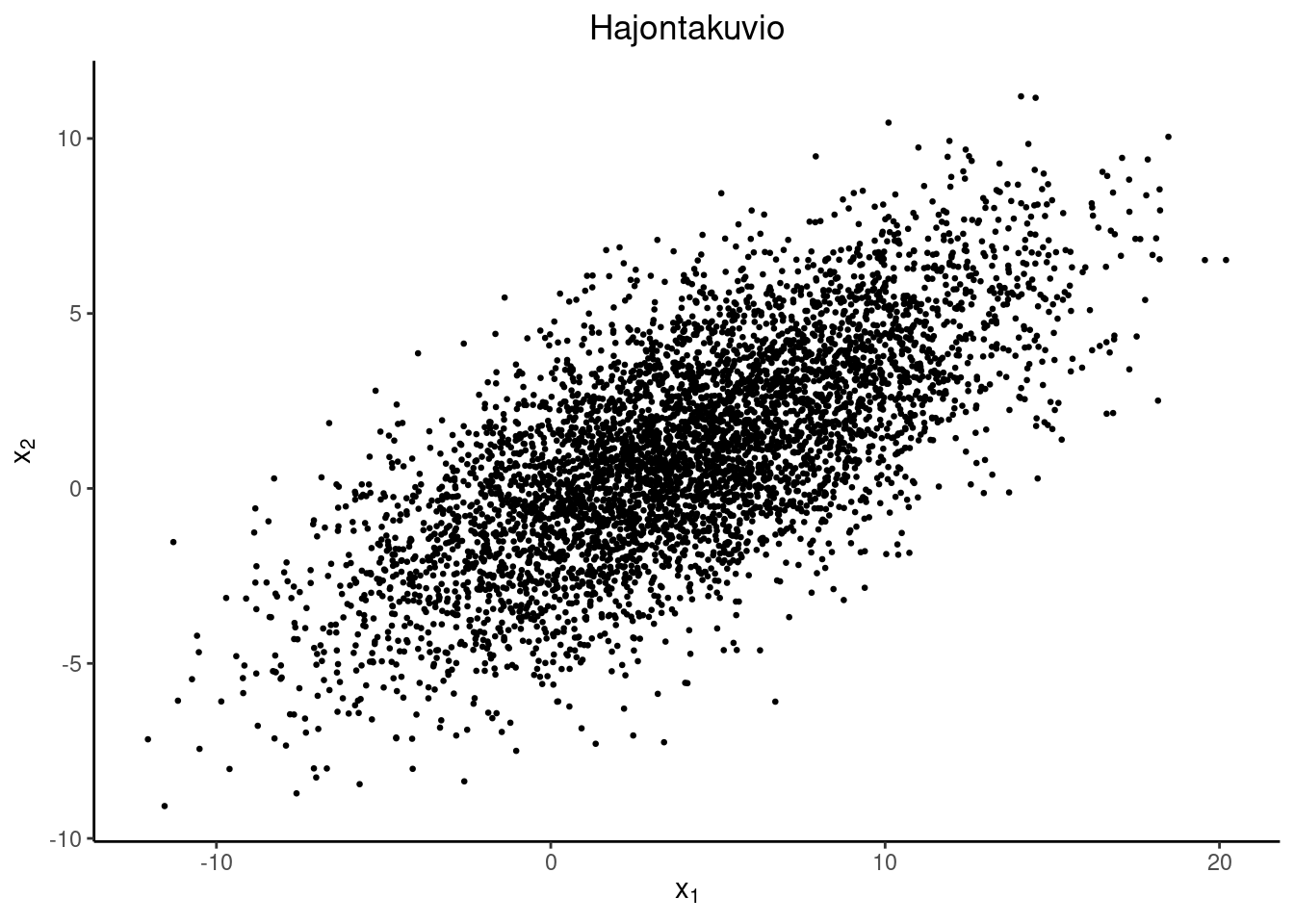
Esimerkki 3.1 (Kaksiulotteisen normaalijakauman simulointi) Oletetaan, että \[ \begin{pmatrix} X_1 \\ X_2 \end{pmatrix} \sim \operatorname{N}_2(\mu, \Sigma),\, \mu = \begin{pmatrix} \mu_1 \\ \mu_2 \end{pmatrix},\, \Sigma = \begin{pmatrix} \sigma_1^2 & \sigma_{12} \\ \sigma_{12} & \sigma_2^2 \end{pmatrix}. \] On laskettava ehdolliset jakaumat. Tässä tapauksessa saadaan: \[ \begin{aligned} X_1|X_2 &= x_2 \sim \operatorname{N}\left(\mu_1 + \frac{\sigma_1}{\sigma_2}\rho(x_2-\mu_2),(1-\rho^2)\sigma_1^2 \right) \\ X_2|X_1 &= x_1 \sim \operatorname{N}\left(\mu_2 + \frac{\sigma_2}{\sigma_1}\rho(x_1-\mu_1),(1-\rho^2)\sigma_2^2 \right), \end{aligned} \] missä \(\rho = \dfrac{\sigma_{12}}{\sigma_1 \sigma_2}\) on korrelaatiokerroin.
Simulointi etenee seuraavasti: Olkoon alkuarvo \((x_1^{(0)},x_2^{(0)})^T\). \[ \begin{pmatrix} x_1^{(0)} \\ x_2^{(0)} \end{pmatrix} \rightarrow \begin{pmatrix} x_1^{(1)} \\ x_2^{(0)} \end{pmatrix} \rightarrow \begin{pmatrix} x_1^{(1)} \\ x_2^{(1)} \end{pmatrix} \rightarrow \begin{pmatrix} x_1^{(2)} \\ x_2^{(1)} \end{pmatrix} \rightarrow \cdots \] Simuloinnin voi toteuttaa esimerkiksi R-ohjelmistolla seuraavasti
norm_sim <- function(mu, S, x_0, n_sim, n_burn)
{
x <- matrix(ncol = 2, nrow = n_burn + n_sim)
x[1, ] <- x_0
s1 <- sqrt(S[1,1]) # x1:n keskihajonta
s2 <- sqrt(S[2,2]) # x2:n keskihajonta
s12 <- S[1,2] # kovarianssi
rho <- s12 / (s1 * s2) # korrelaatiokerroin
for (i in 2:(n_burn + n_sim))
{
x[i,1] <- rnorm(n = 1,
mean = mu[1] + s1 / s2 * rho * (x[i-1,2] - mu[2]),
sd = sqrt(1-rho^2) * s1)
x[i,2] <- rnorm(n = 1,
mean = mu[2] + s2 / s1 * rho * (x[i,1] - mu[1]),
sd = sqrt(1-rho^2) * s2)
}
return(x[(n_burn+1):(n_burn+n_sim), ])
}
mu <- c(4, 1)
S <- matrix(c(25, 10.5, 10.5, 9), ncol = 2)
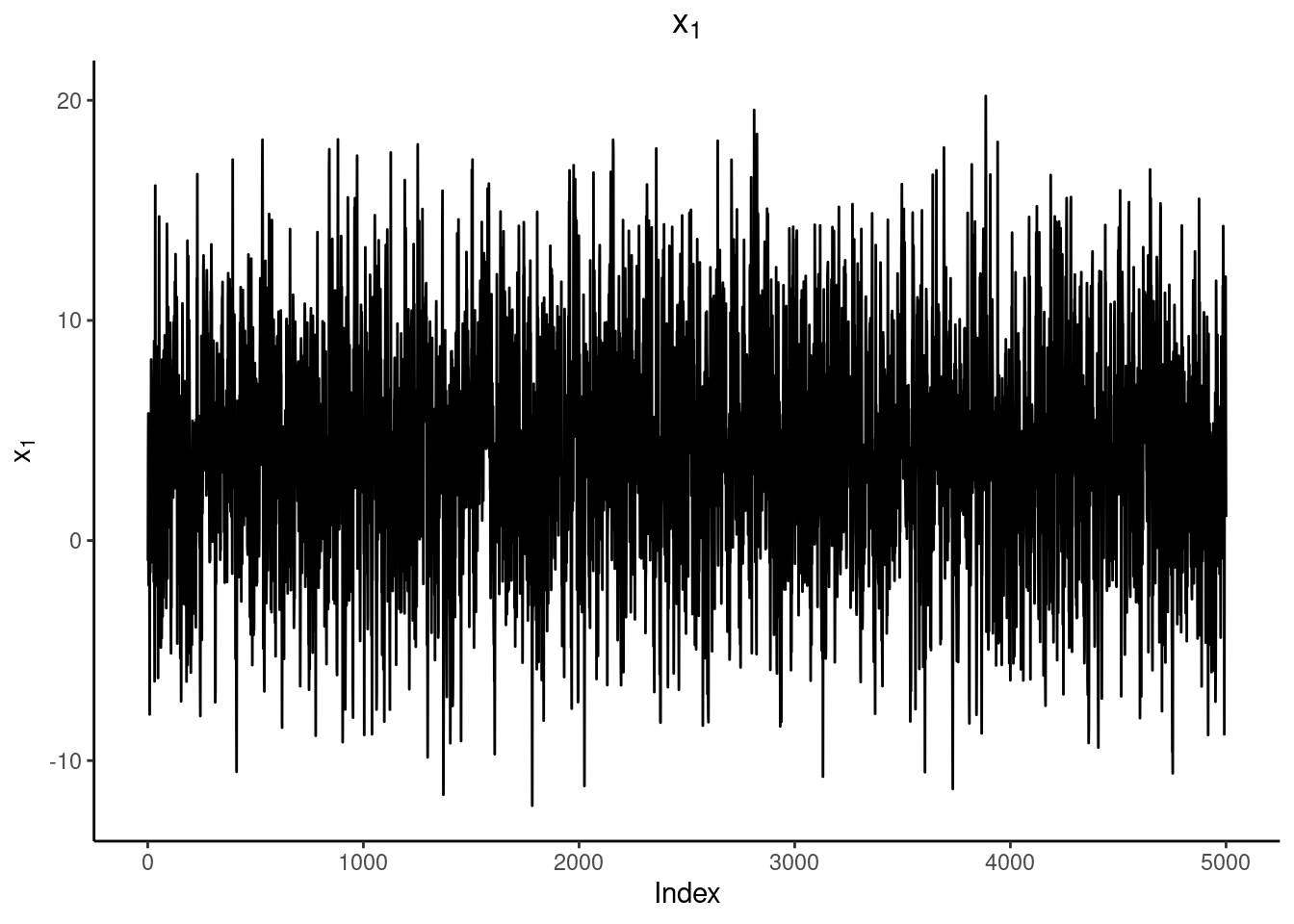
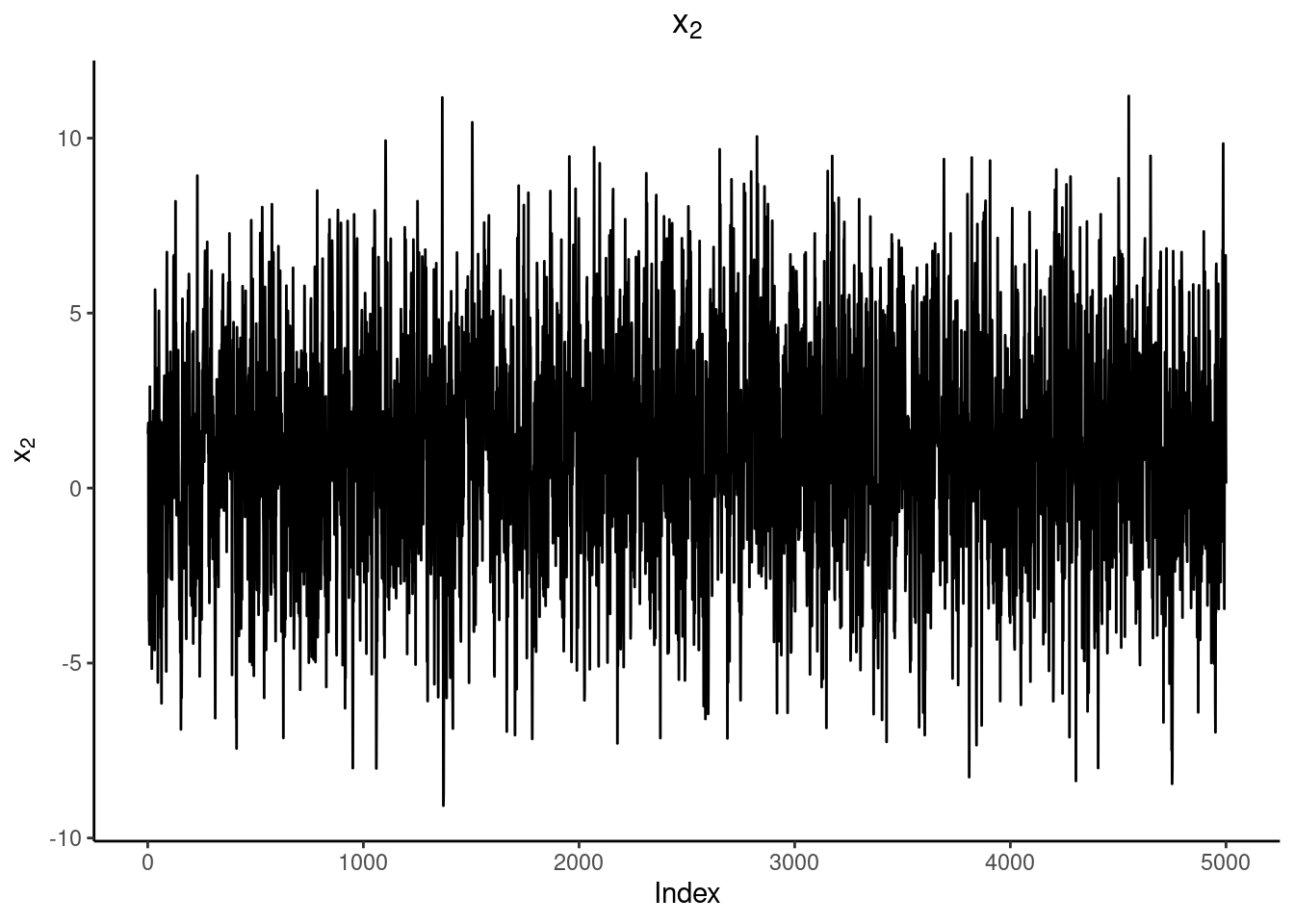
tul <- norm_sim(mu, S, c(0, 0), 5e3, 1e3)| Mean | SD | |
|---|---|---|
| \(x_1\) | 4.080825 | 4.985672 |
| \(x_2\) | 1.095280 | 3.038695 |
3.5 Metropolis-algoritmi
Metropolis-algoritmissa käytetään ehdotusjakaumaa, josta generoidaan ehdotuksia Markovin ketjun seuraavaksi tilaksi. Ehdotus voidaan hyväksyä tai hylätä. Jälkimmäisessä tapauksessa seuraava tila on sama kuin nykyinen tila. Algoritmi perustuu siihen, että posteriorijakaumien suhde voidaan laskea normeeraamattomien posteriorijakaumien avulla, vaikka Bayesin kaavan nimittäjää \(p(y)\) ei tunnettaisikaan. Olkoon \(\theta_a\) ja \(\theta_b\) kaksi parametrin \(\theta\) arvoa. Posteriorijakaumien suhteelle pätee \[ \frac{ p(\theta_b | y) }{ p(\theta_a | y)} = \frac{ p(\theta_b)p(y | \theta_b)/p(y) }{ p(\theta_a)p(y | \theta_a)/p(y)} = \frac{ p(\theta_b)p(y | \theta_b)}{p(\theta_a)p(y | \theta_a)}. \] Algoritmi voidaan esittää seuraavasti:
Aseta alkuarvo \(\theta^{(0)}\) ja aseta \(t=0\).
Toista vaiheita 3–5, iteraatioilla \(t = 1, 2, \ldots, T\).
Generoi ehdotus \(\theta^*\) ehdotusjakaumasta \(q(\theta^* | \theta^{(t)})\). Ehdotusjakauman tulee täyttää symmetrisyysehto \(q(\theta_a | \theta_b) = q(\theta_b | \theta_a)\) kaikilla \(\theta_a\), \(\theta_b\).
Laske hyväksymistodennäköisyys normeeraamattomien posteriorijakaumien avulla \[ \alpha = \min \left\{1, \frac{p(\theta^*)p(y | \theta^*)}{p(\theta^{(t)})p(y | \theta^{(t)})} \right\} \]
Aseta \[ \theta^{(t+1)}= \begin{cases} \theta^* & \text{todennäköisyydellä } \alpha, \\ \theta^{(t)} & \text{muutoin.} \end{cases} \] Metropolis-algoritmi toteuttaa lokaalin tasapainoehdon. Tämän osoittamiseksi tarkastellaan Markovin ketjun siirtymätodennäköisyyksiä
\[ P(\theta^* | \theta^{(t)}) = \begin{cases} q(\theta^* | \theta^{(t)}) \min \left\{1, \frac{p(\theta^*)p(y | \theta^*)}{p(\theta^{(t)})p(y | \theta^{(t)})} \right\}, & \theta^* \neq \theta^{(t)}, \\ q(\theta^{(t)} | \theta^{(t)}) + \sum_{\theta' \neq \theta^{(t)}} q(\theta' | \theta^{(t)}) \left(1- \min \left\{1, \frac{p(\theta')p(y | \theta')}{p(\theta^{(t)})p(y | \theta^{(t)})} \right\}\right), & \theta^* = \theta^{(t)}. \end{cases} \] Lokaalin tasapaino edellyttää ehdon \(p(\theta^{(t)} | y)P(\theta^* | \theta^{(t)})=p(\theta^* | y)P(\theta^{(t)} | \theta^*)\) voimassaoloa. Jos \(\theta^* = \theta^{(t)}\), ehto toteutuu suoraan. Tilanteessa \(\theta^* \neq \theta^{(t)}\) saadaan \[ \begin{aligned} p(\theta^{(t)} | y)P(\theta^* | \theta^{(t)}) & = p(\theta^{(t)} | y) q(\theta^* | \theta^{(t)}) \min \left\{1, \frac{p(\theta^* | y)}{p(\theta^{(t)} | y)} \right\} \\ & = q(\theta^{(t)} | \theta^*) \min \left\{p(\theta^* | y),p(\theta^{(t)} | y) \right\} \\ & = p(\theta^* | y) q(\theta^{(t)} | \theta^*) \min \left\{1, \frac{p(\theta^{(t)} | y)}{p(\theta^* | y)} \right\} \\ & = p(\theta^* | y)P(\theta^{(t)} | \theta^*), \end{aligned} \] missä toisella rivillä on käytetty ehdotusjakauman symmetrisyysominaisuutta \(q(\theta^* | \theta^{(t)})=q(\theta^{(t)} | \theta^*)\).
3.6 Metropolis-Hastings-algoritmi
Metropolis-Hastings-algoritmissa Metropolis-algoritmia muokataan siten, että ehdotusjakauman ei tarvitse täyttää symmetrisyysehtoa. Algoritmi voidaan esittää seuraavasti:
Aseta alkuarvo \(\theta^{(0)}\) ja aseta \(t=0\).
Toista vaiheita 3–5, iteraatioilla \(t=1,2,\ldots,T\).
Generoi ehdotus \(\theta^*\) ehdotusjakaumasta \(q(\theta^* | \theta^{(t)})\). Ehdotusjakauman ei tarvitse täyttää symmetrisyysehtoa.
Laske hyväksymistodennäköisyys ehdotusjakauman ja normeeraamattomien posteriorijakaumien avulla \[ \alpha = \min \left\{1, \frac{p(\theta^*)p(y | \theta^*)q(\theta^{(t)} | \theta^*)}{p(\theta^{(t)})p(y | \theta^{(t)})q(\theta^* | \theta^{(t)})} \right\} \]
Aseta \[ \theta^{(t+1)}= \begin{cases} \theta^* & \text{todennäköisyydellä } \alpha, \\ \theta^{(t)} & \text{muutoin.} \end{cases} \]
Metropolis-Hastings-algoritmia voidaan käyttää Gibbsin algoritmin osana. Parametri, jonka ehdollista jakaumaa ei kyetä laskemaan, voidaan päivittää Metropolis-Hastings-algoritmilla. Toisaalta Gibbsin algoritmi voidaan nähdä Metropolis-Hastings-algoritmin varianttina, jossa ehdotukset tuotetaan komponenteittain ehdollisista jakaumista ja hyväksytään todennäköisyydellä 1.
3.7 Ketjun suppenemisen tarkastelu
MCMC-menetelmiä käytettäessä tulee varmistaa, että ketju on supennut tasapainojakaumaan. Ketjun alkupään havainnot eivät ole peräisin tasapainojakaumasta eikä niitä tästä syystä tule käyttää posteriorijakaumaa estimoitaessa. Ketjun alkua kutsutaan nimellä lämmitys tai sisäänajo (englanniksi burn-in tai warm-up). Monet ohjelmistot poistavat oletusarvoisesti ketjun ensimmäisen puoliskon, ellei käyttäjä toisin määrää.
Ensimmäinen tapa arvioida ketjun suppenemista on silmämääräinen tarkastelu. Ketjun tulisi näyttää satunnaiselta vaihtelulta vakiona pysyvän keskiarvon ympärillä. Silmämääräisen tarkastelun avulla on usein mahdollista todeta, että ketju ei ole vielä supennut, mutta suppenemisen varmistaminen pelkästään tällä tavalla ei ole täysin luotettavaa. On yleistä, että jokin mallin parametri on supennut mutta jokin toinen parametri ei ole. Kaikkien parametrien systemaattinen tarkastelu kuvaajien avulla voi viedä paljon aikaa, koska Bayes-malleissa usein satoja tai tuhansia parametreja.
Edistyneemmät suppenemistarkastelut vaativat usean eri ketjun käyttämistä. Ketjujen alkuarvojen tulisi selvästi poiketa toisistaan, jotta alkuarvojen vaikutusta suppenemiseen voidaan tarkastella. Samaa alkuarvoa käytettäessä osa mahdollisista ongelmista voi jäädä huomaamatta. Ketjujen käyttäytymistä voi edelleen tarkastella silmämääräisesti esimerkiksi piirtämällä (saman parametrin) eri ketjut samaan kuvaan. Suppenemisen tarkastelemiseen on myös ehdotettu erilaisia tunnuslukuja, joista seuraavaksi esitellään usean ohjelmiston käyttämä tunnusluku mahdollisen skaalan pienenemisen kerroin \(\hat{R}\) (potential scale reduction factor).
Tunnusluku perustuu ketjujen sisäisen ja ketjujen välisen vaihtelun vertaamiseen. Olkoon käytössä \(m\) ketjua, joiden pituus lämmitysjakson poistamisen jälkeen on \(n\). Skalaariparametrista \(\theta\) on käytössä simuloidut arvot \(\theta^{(ij)}\), \(i=1,\ldots,n\), \(j=1,\ldots,m\). Ketjujen välistä vaihtelua kuvaa neliösumma
\[\begin{equation}
B = \frac{n}{m-1} \sum_{j=1}^m (\overline{\theta}^{(\cdot j)}-\overline{\theta}^{(\cdot \cdot)})^2, \textrm{ missä } \overline \theta^{(\cdot j)}=\frac{1}{n} \sum_{i=1}^n \theta^{(ij)} \textrm{ ja } \overline \theta^{(\cdot \cdot)}=\frac{1}{m} \sum_{j=1}^m \overline \theta^{(\cdot j)}.
\tag{3.1}
\end{equation}\]
Ketjujen sisäistä vaihtelua kuvaa neliösumma
\[ W=\frac{1}{m} \sum_{j=1}^m s_j^2, \textrm{ missä } s_j^2=\frac{1}{n-1} \sum_{i=1}^n (\theta^{(ij)}-\overline{\theta}^{(\cdot j)})^2. \]
Sisäinen varianssi \(W\) aliestimoi posteriorivarianssia \(\operatorname{Var}(\theta | y)\), koska äärellinen ketju ei välttämättä ole käynyt läpi koko parametriavaruutta. Sen sijaan estimaattori
\[ V = \frac{n-1}{n}W + \frac{1}{n}B\]
yliestimoi posteriorivarianssia. Sekä \(W\) että \(V\) ovat posteriorivarianssin tarkentuvia estimaattoreita. Tunnusluku \(\hat{R}\) perustuu näiden kahden estimaattorin suhteeseen
\[
\hat{R} = \sqrt{\frac{V}{W}},
\]
joka suppenee kohti arvoa 1, kun \(n \rightarrow \infty\). Käytännössä ketjun katsotaan supenneen, jos \(\hat{R}<1.05\) kaikille parametreille. Mahdollisen skaalan pienenemisen kertoimelle on myös esitetty korjaus, joka ottaa huomion otantavaihtelun varianssiestimaateissa. Korjattu kerroin määritellään seuraavasti
\[
\hat{R}_c = \sqrt{\frac{(d+3)V}{(d+1)W}},
\]
missä \(d = 2V/\operatorname{Var}(V)\). Korjatun kertoimen muutosta voi tarkastella R:ssä esimerkiksi coda-paketin funktiolla gelman.diag.
3.8 Tehokas otoskoko
Koska Markovin ketjut tuottavat riippuvia havaintoja, otos sisältää tyypillisesti vähemmän informaatiota kuin samankokoinen otos riippumattomia havaintoja. Tehokkaan otoskoon tarkoituksena on kertoa, kuinka suurta riippumatonta otosta käytettävissä oleva ketju vastaa. Esimerkiksi Stan estimoi tehokkaan otoskoon automaattisesti. Tehokkaan otoskoon voi estimoida esimerkiksi myös coda-paketin funktiolla effectiveSize.
Mikäli ketju on tasapainotilassa, riippuvuudella ei ole vaikutusta odotusarvoon. Ketjujen välinen vaihtelu \(B\) (kaava (3.1)) sen sijaan on suurempaa kuin riippumattomalla otoksella. Mitä suurempi ketjujen autokorrelaatio on, sitä enemmän \(B\) poikkeaa riippumattoman otoksen vaihtelusta.
Tehokas otoskoko määritellään ketjun autokorrelaation avulla eri viiveitä (lags) tarkastelemalla. Viiveen \(k \geq 0\) autokorrelaatio \(\rho_k\) ketjulle, jonka yhteisjakauman on \(p(\theta)\) odotusarvolla \(\mu\) ja varianssilla \(\sigma^2\), määritellään seuraavasti \[\begin{equation} \rho_k = \frac1{\sigma^2} \int_S (\theta^{(t)} - \mu)(\theta^{(t + k)} - \mu)p(\theta)\, d\theta. \tag{3.2} \end{equation}\] Autokorrelaatio mittaa ketjujen \(\theta^{(t)}\) ja \(\theta^{(t+k)}\) välistä korrelaatiota, eli siis alkuperäisen ketjun \(\theta^{(t)}\) ja siitä \(k\) indeksiä siirtämällä saadun ketjun välistä korrelaatiota.
Otoskokoa \(n\) vastaava tehokas otoskoko määritellään autokorrelaatioiden avulla seuraavasti: \[ n_\textrm{eff} = \frac{n}{\sum_{k = -\infty}^\infty \rho_k} = \frac{n}{1 + 2\sum_{k = 1}^\infty \rho_k}. \] Otoksesta laskettuja autokorrelaatioita käyttämällä tehokkaalle otoskoolle voidaan johtaa estimaattori \[ \hat{n}_\textrm{eff}=\frac{mn}{1+2 \sum_{k=1}^K \hat{\rho}_k}, \] missä \(\hat{\rho}_k\) on estimaatti viiveen \(k\) autokorrelaatiolle joka on laskettu \(m\) ketjusta. Estimoinnissa käytetty maksimiviive \(K\) on pienin pariton luku, jolle \(\hat{\rho}_{K+1}+\hat{\rho}_{K+2}<0\).