
Binääripuu ja lisättävä alkio
Funktio-ohjelmoinnissa on käytännössä kaksi tapaa määritellä tietorakenteita. Ensimmäinen tapa on käyttää IO-monadia tai jotain vastaavaa abstraktiota, joka tarjoaa muuttuvia arvoja ja määritellä rakenteet samalla tavalla kuin algoritmikursseilla esitetään. Toinen tapa on siirtyä käyttämään säilyväisiä tai versioituvia tietorakenteita.
Versioituvat tietorakenteet ovat samalla tavalla muuttumattomia kuin muutkin funktio-ohjelmoinnin arvot ja niiden tehokas käyttö pohjautuu siihen, että niiden kopiointi voidaan tehdä muiden operaatioiden yhteydessä nopeasti. Esimerkiksi binääripuu toimii siten, että kun siihen lisätään alkio, luodaan uudestaan vain ne solmut, joiden kautta kuljetaan ja säilötään viitteet vanhan puun solmuihin, silloin kuin mahdollista.
Tällä tavalla saavutetaan usein sama asymptoottinen aikavaativuus kuin muuttuvilla tietorakenteillakin, joskin tietyt rakenteet, kuten hyppylistat tai hajautustaulut ovat osoittautuneet hyvin hankaliksi toteuttaa tällä tavalla. Kuten edellä olevasta kuvasarjasta havaitaan, tällä tavalla voimme säilyttää myös vanhan binääripuumme. Tästä on huomattavaa etua esimerkiksi silloin, kun toteutamme peruuttavia algoritmeja — pääsemme edellisen iteraation tilaan ilman mitään lisätyötä.
Jälleen, funktio-ohjelmoinnin viite-eheys auttaa meitä suunnittelemaan ja varmistamaan algoritmiemme oikeellisuuden.
Binääripuu ja lisättävä alkio
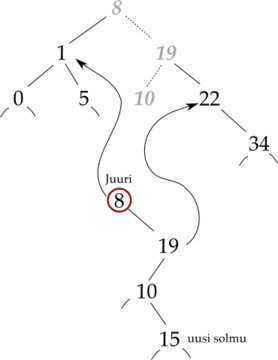
Kaksi binääripuuta, joissa toisessa on lisätty alkio

Tilanne roskienkeruun jälkeen
Tämän kappaleen lähtötiedot löydät Chris Okasakin väitöskirjasta Purely Functional Data Structures tai samannimisesta, hieman täydellisemmästä kirjasta.
Toteutetaan muutama yksinkertainen tietorakenne ja pakataan ne moduleiksi. Haskellissa on yleensä tapana varmistaa tietorakenteiden oikea-oppinen käyttö siten, että ne kirjoitetaan omaan moduliinsa, jossa ei ole muuta koodia ja joka ei julkaise tietorakenteiden konstruktoreita lainkaan. Ainoastaan abstraktit operaatiot esitetään. Esimerkkinä pino:
> module TIES341.DataStructures.Stack
> (Stack, emptyStack, push, top, pop, empty) where
> import Test.QuickCheck -- Tätä tarvitaan hieman myöhemmin> newtype Stack a = Stack [a] deriving (Eq,Show)> emptyStack = Stack []> push (Stack xs) x = Stack (x:xs)> top (Stack []) = error "Empty stack"
> top (Stack (x:xs)) = x> pop (Stack []) = Stack []
> pop (Stack (x:xs)) = Stack xs> empty (Stack xs) = null xsUsein on hyvä osoittaa testaamalla tai todistamalla, että tietorakenne toimii. Lainalaisuuksien keksiminen on oma taiteenlajinsa, mutta olennaisimmat löytyvät yleensä helposti. Pinon aksioomat ovat seuraavat:
{- kaikille x ja s -}
top (push s x) == x
pop (push x s) == s
empty (push x s) == FalseNäiden todistaminen onnistuu laskemalla. Esimerkkinä ensimmäinen pino-aksiooma:
{- Olkoon x mielivaltainen alkio ja s mielivaltainen pino Stack xs -}
top (push (Stack xs) x)
== {- push, määritelmä -}
top (Stack (x:xs))
=={- top, määritelmä -}
xMonimutkaisten tietorakenteiden kanssa todistaminen on työlästä ja sitä tulee käyttää vain kriittisissä tilanteissa tahi harjoittelun vuoksi. Onneksi vastaavanlaiset lainalaisuudet voidaan helposti testata käyttämällä esimerkiksi Quickcheck tai SmallCheck moduleita. Näistä ensimmäinen on yleisimmin käytetty, mutta jälkimmäinen on erityisen kätevä omien tietotyyppien kanssa.
Toisen pino-aksiooman automaattinen testaaminen Quickcheck-modulilla kävisi näin:
axiom2 :: Int -> Stack Int -> Bool
axiom2 = \x s -> pop (push s x) == sValitettavasti, QuickCheck ei tiedä miten pinoja luodaan, joten joudumme huijaamaan hieman ja rakentamaan pinon mielivaltaisesta listasta:
> axiom2 :: Int -> [Int] -> Bool
> axiom2 = \x xs -> pop (push (Stack xs) x) == Stack xsJa itse testaustapahtuma
quickCheck axiom2
=>
+++ OK, passed 100 tests.Eli sadalla automaattisesti generoidulla satunnaistestillä ominaisuus piti paikkansa. Voimme myös opettaa QuickCheckille, miten pinoja luodaan määrittelemällä niille Arbitrary tyyppiluokan toteutuksen:
> instance Arbitrary a => Arbitrary (Stack a) where
> arbitrary = fmap Stack arbitraryjolloin ensimmäinenkin testitapauksen määritelmä toimisi.
Toteutetaan FIFO-jono.
Binomikeko on hauska prioriteettijonorakenne.
merge, joka yhdistää kaksi binomikekoatop, joka palauttaa pienimmän alkionqueue, joka lisää alkion jonoon.dequeue, joka poistaa pienimmän alkionTODO: Keksi parempi
Tehtävä — Binääripuut
Tietorakenteiden yhteydessä oikeellisuuden jälkeen kiinnostaa eniten suorituskyky. Tätä voidaan tutkia kahdella tavalla, matemaattisluonteisella analyysillä ja empiirisellä testaamisella. Molemmat on hyvä hallita, ensimmäinen jo sen takia, että se opettaa ajattelemaan aikavaatimuksia jo ohjelmoidessa. Tässä kohtaa on hyvä paneutua Purely Functional Data Structures opuksen lukuun 3.4. ennen tehtävien tekemistä.
Tutkitaan aluksi todella yksinkertaista tietorakennetta ja algoritmia, nimittäin binäärilaskuria:
> type Counter = [Int]
> inc [] = [1]
> inc (0:xs) = (1:xs)
> inc (1:xs) = (0:inc xs)Esimerkiksi:
inc [] == [1]
inc . inc $ [] == [0,1]
inc . inc . inc $ [] == [1,1]Seuraavaksi osoitamme, että inc-operaation aikavaativuus on keskimäärin O(1), eli inc vie keskimäärin jonkin vakio-ajan. Koska se ei vie sitä aina, käytämme ns. Pankkiirin menetelmää ja todistus menee karkeasti näin:
Olettakaamme, että bitin vaihtaminen tai lisääminen vaatii yhden yksikön aikaa. Koska joskus joudumme
vaihtamaan useampia yhtä `inc` operaatiota kohden, niin laskutetaan niistä jokaisesta *kaksi* yksikköä:
Jos joudumme vaihtamaan 0-bitin 1-bitiksi, talletetaan ylimääräinen aika-yksikkö odottamaan ykkösbitille. Jos
vaihdamme 1-bitin nollabitiksi, käytämme yhden aika-yksikön bitin vaihtoon ja otamme talletetun aikayksikön
ja käytämme sen vaihtaaksemme seuraavan bitin.
Täten, voimme keskimäärin kahdella aikayksiköllä/`inc` hoitaa minkä tahansa `inc` operaatiojonon kustannukset.